I want to create a pivot with average values over multiple tables. Here is an example that I want to create: Inputs are df1 and df2, res is the result I want to calculate from df1 and df2
import pandas as pd
import numpy as np
df1 = pd.DataFrame({"2000": ["A", "A", "B"],
"2001": ["A", "B", "B"],
"2002": ["B", "B", "B"]},
index =['Item1', 'Item2', 'Item3'])
df2 = pd.DataFrame({"2000": [0.5, 0.7, 0.1],
"2001": [0.6, 0.6, 0.3],
"2002": [0.7, 0.4, 0.2]},
index =['Item1', 'Item2', 'Item3'])
display(df1)
display(df2)
res = pd.DataFrame({"2000": [0.6, 0.1],
"2001": [0.6, 0.45],
"2002": [np.nan, 0.43]},
index =['A', 'B'])
display(res)
Both dataframes have years in columns. Each row is an item. The items change state over time. The state is defined in df1. They also have values each year, defined in df2. I want to calculate the average value by year for each group of states A, B.
I did not achieve to calculate res, any suggestions?
CodePudding user response:
To solve this problem you should merge both DataFrames in one, at first. For example you can use this code convert dataframe from wide to long and then merge both of them by the index (year, item), and finally reset the index to be used as a column in the pivot:
df_full = pd.concat([df1.unstack(), df2.unstack()], axis=1).reset_index()
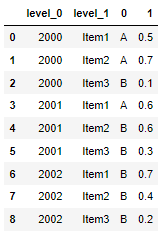
Then, if you want, you can rename columns to build a clear pivot:
df_full = df_full.rename(columns={'level_0': 'year', 'level_1': 'item', 0: 'DF1', 1:'DF2'})
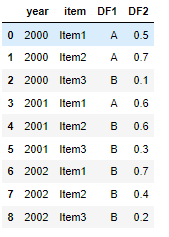
And finally build a pivot table.
res_out = pd.pivot_table(data=df_full, index='DF1', columns='year', values='DF2', aggfunc='mean')
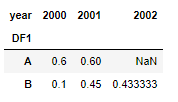
It's not a one line solution, but it works.
df_full = pd.concat([df1.unstack(), df2.unstack()], axis=1).reset_index()
df_full = df_full.rename(columns={'level_0': 'year', 'level_1': 'item', 0: 'DF1', 1:'DF2'})
res_out = pd.pivot_table(data=df_full, index='DF1', columns='year', values='DF2', aggfunc='mean')
display(res_out)
CodePudding user response:
This code using stack, join and unstack should work:
df1_long = df1.stack().to_frame().rename({0:'category'}, axis=1)
df2_long = df2.stack().to_frame().rename({0:'values'}, axis=1)
joined_data = df1_long.join(df2_long).reset_index().rename({'level_0':'item','level_1':'year'}, axis=1)
res = joined_data.groupby(['category', 'year']).mean().unstack()
display(res)