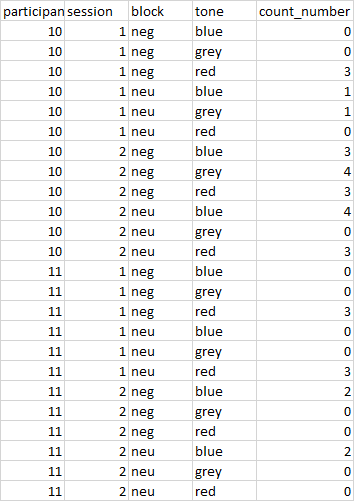
Hi I have a dataframe that looks like this:
and I want to calculate a ratio in the column 'count_number', based on the values in the column 'tone' by this formula: ['blue' 'grey']/'red' per each unite combination of 'participant_id', 'session', 'block' -
here is part of my dataset as text, the left column 'RATIO' is my expected output:
participant_id session block tone count_number RATIO 10 1 neg blue 0 0 10 1 neg grey 0 0 10 1 neg red 3 0 10 1 neu blue 1 #DIV/0! 10 1 neu grey 1 #DIV/0! 10 1 neu red 0 #DIV/0! 10 2 neg blue 3 2.333333333 10 2 neg grey 4 2.333333333 10 2 neg red 3 2.333333333 10 2 neu blue 4 1.333333333 10 2 neu grey 0 1.333333333 10 2 neu red 3 1.333333333 11 1 neg blue 0 0 11 1 neg grey 0 0 11 1 neg red 3 0
I tried this (wrong) direction
def group(df):
grouped = df.groupby(["participant_id", "session", "block"])['count_number']
return grouped
neutral = df.loc[df.tone=='grey']
pleasant = df.loc[df.tone=='blue']
unpleasant = df.loc[df.tone=='red']
df['ratio'] = (group(neutral) group(pleasant)) / group(unpleasant)
CodePudding user response:
Here's one approach:
groupby apply a lambda that calculates the required ratio for each group; then map the ratios back to the original DataFrame:
cols = ['participant_id', 'session', 'block']
mapping = (df.groupby(cols)
.apply(lambda x: (x.loc[x['tone'].isin(['blue','grey']), 'count_number'].sum() /
x.loc[x['tone'].eq('red'), 'count_number']))
.droplevel(-1))
df['RATIO'] = df.set_index(cols).index.map(mapping)
df['RATIO'] = df['RATIO'].replace(float('inf'), '#DIV/0!')
Output:
group participant_id session block tone count_number RATIO
0 1 10 1 neg blue 0 0.0
1 1 10 1 neg grey 0 0.0
2 1 10 1 neg red 3 0.0
3 1 10 1 neu blue 1 #DIV/0!
4 1 10 1 neu grey 1 #DIV/0!
5 1 10 1 neu red 0 #DIV/0!
6 1 10 2 neg blue 3 2.333333
7 1 10 2 neg grey 4 2.333333
8 1 10 2 neg red 3 2.333333
9 1 10 2 neu blue 4 1.333333
10 1 10 2 neu grey 0 1.333333
11 1 10 2 neu red 3 1.333333
12 1 11 1 neg blue 0 0.0
13 1 11 1 neg grey 0 0.0
14 1 11 1 neg red 3 0.0