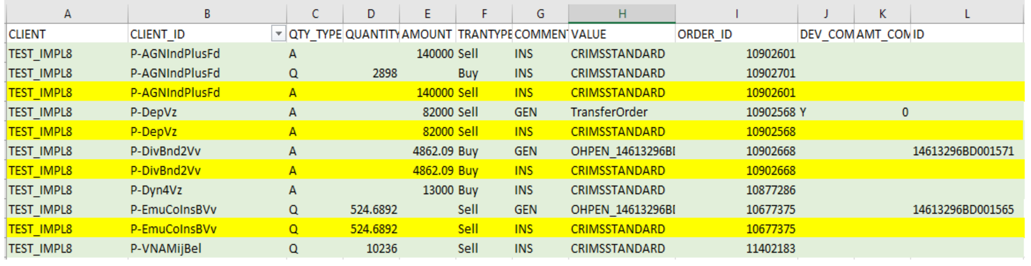
Hi, I have this data where I have to remove the duplicate data highlighted in yellow. I tried to use distinct and group by but it does not seem to work. Can you please help me out with duplicate data removal in this case please? Even though the comment and value is different, anything having the value as CRIMSSTANDARD is considered a child of the parent in this case and hence considered as a duplicate as the first 6 fields are the same. How do I remove the duplicate records in this case?
CLIENT;CLIENT_ID;QTY_TYPE;QUANTITY;AMOUNT;TRANTYPE;COMMENT;VALUE;ORDER_ID;DEV_COMM;AMT_COMM;ID
TEST_IMPL8;P-AGNIndPlusFd;A;;140000;Sell;INS;CRIMSSTANDARD;10902601;;;
TEST_IMPL8;P-AGNIndPlusFd;Q;2898;;Buy;INS;CRIMSSTANDARD;10902701;;;
TEST_IMPL8;P-AGNIndPlusFd;A;;140000;Sell;INS;CRIMSSTANDARD;10902601;;;
TEST_IMPL8;P-DepVz;A;;82000;Sell;GEN,TransferOrder;10902568;Y;0;
TEST_IMPL8;P-DepVz;A;;82000;Sell;INS;CRIMSSTANDARD;10902568;;;
TEST_IMPL8;P-DivBnd2Vv;A;;4862.09;Buy;GEN;OHPEN_14613296BD001571;10902668;;;14613296BD001571
TEST_IMPL8;P-DivBnd2Vv;A;;4862.09;Buy;INS;CRIMSSTANDARD;10902668;;;
TEST_IMPL8;P-Dyn4Vz;A;;13000;Buy;INS;CRIMSSTANDARD;10877286;;;
TEST_IMPL8;P-EmuCoInsBVv;Q;524.6892;;Sell;GEN;OHPEN_14613296BD001565;10677375;;;14613296BD001565
TEST_IMPL8;P-EmuCoInsBVv;Q;524.6892;;Sell;INS;CRIMSSTANDARD;10677375;;;
TEST_IMPL8;P-VNAMijBel;Q;10236;;Sell;INS;CRIMSSTANDARD;11402183;;;
CodePudding user response:
There is no distinct on in Snowflake, but you can have a similar result using qualify:
SELECT * FROM my_table
QUALIFY ROW_NUMBER() OVER (
PARTITION BY client, client_id, qty_type, quantity, amount, trantype, value
ORDER BY client, client_id, qty_type, quantity, amount, trantype, value
) = 1;
See here to see more details
CodePudding user response:
First pass, you'll need to get rid of rows that are entire duplicates of each other (this will fix the row 1 and row 3 issue in your data where the rows are exactly the same). Use the approach outlined here: How to delete Duplicate records in snowflake database table
Next, try this to eliminate duplicates of first 6 columns, and deleting the child record designated by CRIMSSTANDARD in the COMMENT column:
begin work;
delete from
my_table using (
select
CLIENT,
CLIENT_ID,
QTY_TYPE,
QUANTITY,
AMOUNT,
TRANTYPE
from
my_table
GROUP BY
CLIENT,
CLIENT_ID,
QTY_TYPE,
QUANTITY,
AMOUNT,
TRANTYPE
HAVING
COUNT(*) > 1
) as my_table_dupes
where
my_table.CLIENT = X.CLIENT
AND my_table.CLIENT_ID = my_table_dupes.CLIENT_ID
AND my_table.QTY_TYPE = my_table_dupes.QTY_TYP
AND my_table.QUANTITY = my_table_dupes.QUANTITY
AND my_table.AMOUNT = my_table_dupes.AMOUNT
AND my_table.TRANTYPE = my_table_dupes.TRANTYPE
AND my_table.COMMENT = 'CRIMSSTANDARD'
commit work;