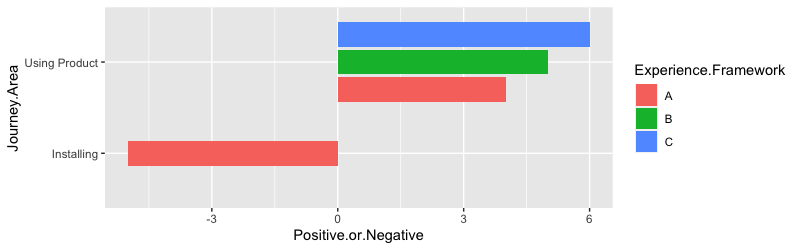
The goal is to make a bar chart from the below data. Data should be clustered into each Customer Journey Area by User Experience Framework. For example, the "Browsing" Journey Area should have an individual bar for each User Experience Framework count. For example, Browsing = Execution (5), Systems (3). Where this gets tricky is that we want to have 0 in the middle and the "Positive hits" going to the right and the "negative hits" going to the left. All bars should be uniform in size.
I can't quite make this happen. Below is my head(df):
> head(df,30)
Journey.Area Experience.Framework Postive.or.Negative
1 Installing People/Associate 1
2 Using Product Execution -1
3 Installing People/Associate 1
4 Delivery Execution -1
5 Installing People/Associate -1
6 Delivery People/Associate 1
7 Installing Execution -1
8 Using Product Execution -1
9 Browsing People/Associate -1
10 Browsing People/Associate -1
11 Browsing People/Associate 1
12 Buying Systems -1
13 Delivery Execution -1
14 Delivery People/Associate 1
15 Installing Execution -1
16 Deciding How to Buy Process/Policy 1
17 Installing People/Associate -1
18 Installing People/Associate 1
19 Delivery Execution -1
20 Buying Process/Policy 1
21 Delivery Execution -1
22 Installing Execution 1
23 Browsing People/Associate 1
24 Installing Execution -1
25 Delivery Execution -1
26 Installing Execution -1
27 Installing Execution -1
28 Deciding How to Buy Process/Policy -1
29 Installing Execution -1
30 Browsing Systems -1
Here is my dput(df):
> dput(df)
structure(list(Journey.Area = c("Installing", "Using Product",
"Installing", "Delivery", "Installing", "Delivery", "Installing",
"Using Product", "Browsing", "Browsing", "Browsing", "Buying",
"Delivery", "Delivery", "Installing", "Deciding How to Buy",
"Installing", "Installing", "Delivery", "Buying", "Delivery",
"Installing", "Browsing", "Installing", "Delivery", "Installing",
"Installing", "Deciding How to Buy", "Installing", "Browsing",
"Delivery", "Installing", "Browsing", "Installing", "Browsing",
"Deciding How to Buy", "Installing", "Anticipating", "Delivery",
"Delivery", "Deciding How to Buy", "Installing", "Using Product",
"Installing", "Delivery", "Installing", "Installing", "Deciding How to Buy",
"Delivery", "Delivery", "Delivery", "Browsing", "Using Product",
"Deciding How to Buy", "Delivery", "Installing", "Installing",
"Deciding How to Buy", "Installing", "Installing", "Anticipating",
"Installing", "Deciding How to Buy", "Deciding How to Buy", "Installing",
"Browsing", "Delivery", "Pickup", "Anticipating", "Deciding How to Buy",
"Using Product", "Installing", "Anticipating", "Deciding How to Buy",
"Browsing", "Deciding How to Buy", "Buying", "Delivery", "Installing",
"Installing", "Installing", "Deciding How to Buy", "Anticipating",
"Delivery", "Installing", "Anticipating", "Delivery", "Delivery",
"Delivery", "Anticipating", "Browsing", "Deciding How to Buy",
"Deciding How to Buy", "Anticipating", "Deciding How to Buy",
"Delivery", "Delivery", "Deciding How to Buy", "Deciding How to Buy",
"Deciding How to Buy"), Experience.Framework = c("People/Associate",
"Execution", "People/Associate", "Execution", "People/Associate",
"People/Associate", "Execution", "Execution", "People/Associate",
"People/Associate", "People/Associate", "Systems", "Execution",
"People/Associate", "Execution", "Process/Policy", "People/Associate",
"People/Associate", "Execution", "Process/Policy", "Execution",
"Execution", "People/Associate", "Execution", "Execution", "Execution",
"Execution", "Process/Policy", "Execution", "Systems", "Execution",
"Execution", "People/Associate", "Execution", "Execution", "Process/Policy",
"Execution", "Systems", "Execution", "Process/Policy", "Process/Policy",
"Execution", "Execution", "Execution", "Execution", "People/Associate",
"Execution", "Execution", "Execution", "Execution", "Execution",
"People/Associate", "Execution", "Process/Policy", "Execution",
"People/Associate", "People/Associate", "People/Associate", "Execution",
"People/Associate", "Process/Policy", "Execution", "Execution",
"Execution", "Execution", "Systems", "Execution", "Execution",
"Execution", "Systems", "Execution", "People/Associate", "Execution",
"Execution", "People/Associate", "People/Associate", "Systems",
"Execution", "Execution", "People/Associate", "Execution", "People/Associate",
"Systems", "Execution", "Execution", "Execution", "Execution",
"Execution", "Execution", "Execution", "Execution", "People/Associate",
"People/Associate", "Execution", "Systems", "Execution", "Execution",
"People/Associate", "People/Associate", "Execution"), Postive.or.Negative = c(1L,
-1L, 1L, -1L, -1L, 1L, -1L, -1L, -1L, -1L, 1L, -1L, -1L, 1L,
-1L, 1L, -1L, 1L, -1L, 1L, -1L, 1L, 1L, -1L, -1L, -1L, -1L, -1L,
-1L, -1L, -1L, -1L, 1L, -1L, 1L, -1L, -1L, -1L, -1L, 1L, 1L,
-1L, -1L, -1L, 1L, -1L, -1L, 1L, -1L, -1L, -1L, -1L, -1L, -1L,
-1L, 1L, 1L, 1L, -1L, 1L, -1L, -1L, 1L, 1L, -1L, -1L, -1L, -1L,
-1L, -1L, 1L, 1L, -1L, 1L, -1L, -1L, -1L, 1L, -1L, -1L, 1L, -1L,
-1L, -1L, -1L, -1L, -1L, 1L, -1L, -1L, -1L, 1L, -1L, -1L, 1L,
-1L, -1L, 1L, 1L, 1L)), class = "data.frame", row.names = c(NA,
-100L))
Again, in the plot all columns should be the same width. Negative counts should go left and Positive counts should go right. Attached is a photo that is close...but you'll notice the bars are different widths.
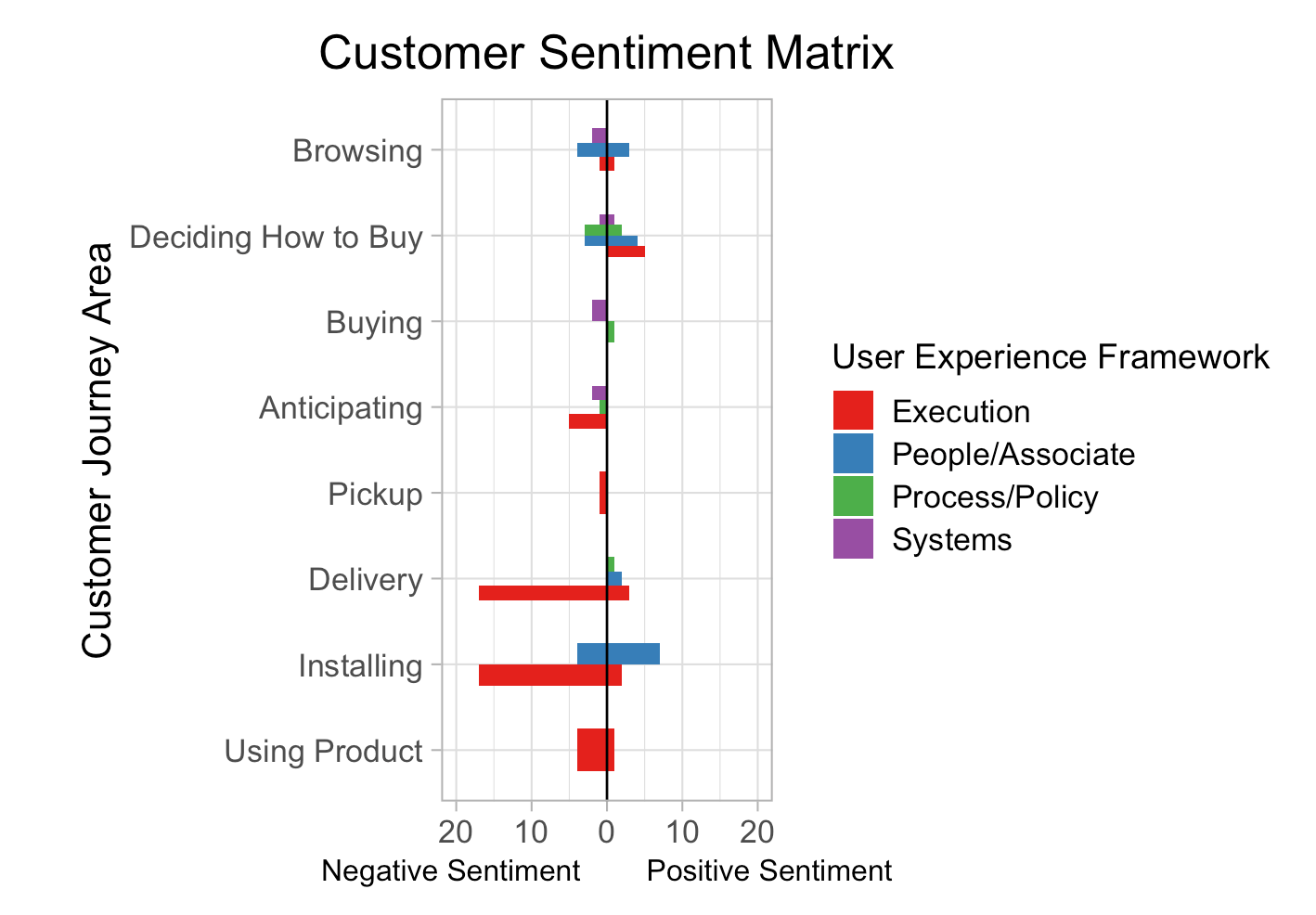
CodePudding user response:
I think you might want geom_col(position = position_dodge2(preserve = "single")).
EDIT:
and you can count the data first to get single bars for each category:
library(tidyverse)
df %>%
count(Journey.Area, Experience.Framework,
wt = Postive.or.Negative, name = "Positive.or.Negative") %>%
ggplot(aes(Positive.or.Negative, Journey.Area, fill = Experience.Framework))
geom_col(position = position_dodge2(preserve = "single"))
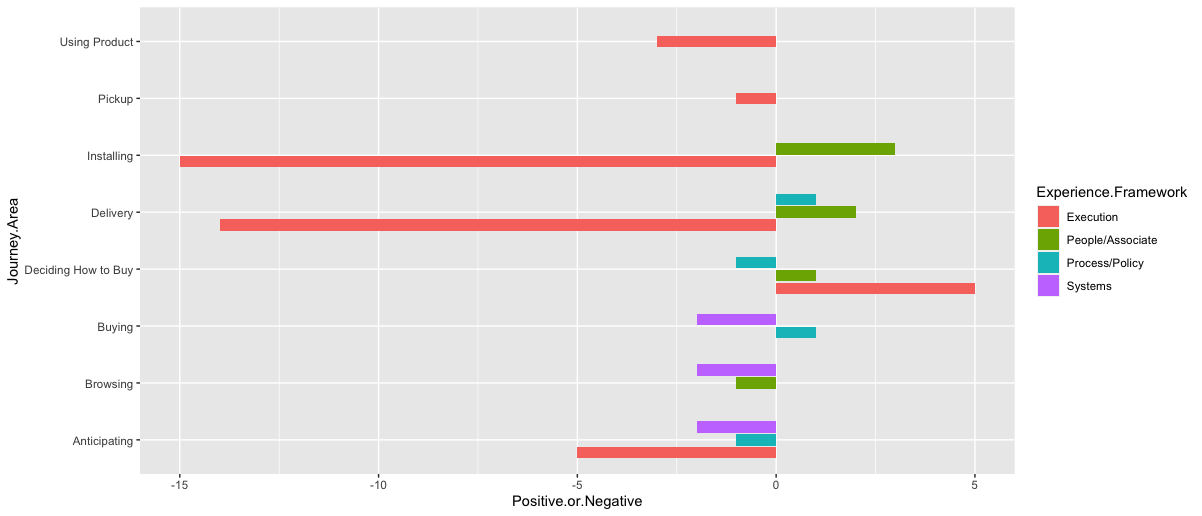
Compare:
data.frame(Journey.Area = c("Installing", rep("Using Product", 3)),
Experience.Framework = c("A","A","B","C"),
Positive.or.Negative = c(-5, 4:6)) %>%
ggplot(aes(Positive.or.Negative, Journey.Area, fill = Experience.Framework))
geom_col(position = "dodge") # (1)
geom_col(position = position_dodge()) # (1)
geom_col(position = position_dodge2()) # (2)
geom_col(position = position_dodge2(preserve = "single")) # (3)
(1)
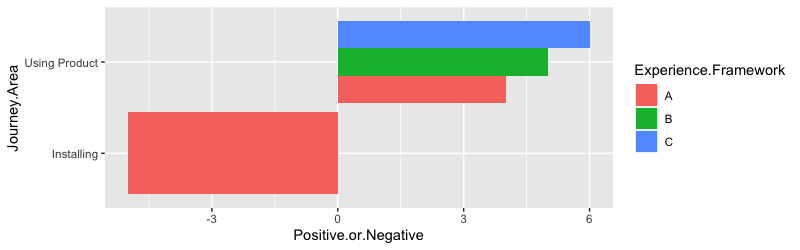
(2)
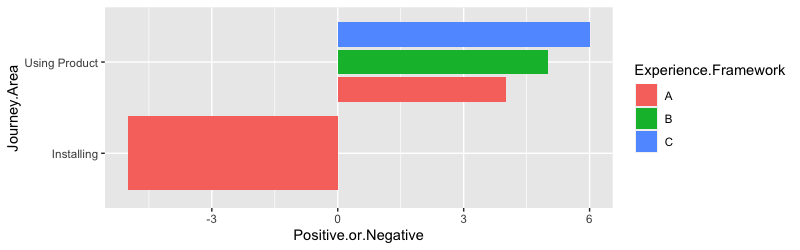
(3)