I have a pandas a dataframe which contains two columns. 1) keywords 2) TopicID.
The keyword is dictionary type. I want to normalize this dataframe in a way that each topic will repeat for each keyword and its value.
My Dataframe

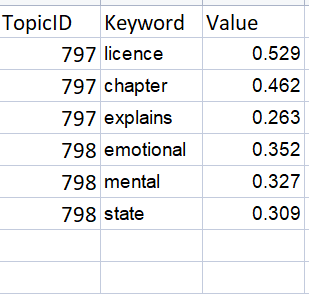
Expected Dataframe (for sample I am posting few keywords only)
I tried this code
df_final = pd.json_normalize(df.keywords.apply(json.loads))
Output of-> print (df[['TopicID','keywords']].head(2).to_dict())
{'TopicID': {0: 797, 1: 798}, 'keywords': {0: {'licence': 0.529, 'chapter': 0.462, 'explains': 0.263, 'visitor': 0.244, 'resident': 0.22, 'applying': 0.205, 'privileges': 0.199, 'graduated': 0.188, 'tests': 0.184, 'licensing': 0.18}, 1: {'emotional': 0.352, 'mental': 0.327, 'state': 0.309, 'operate': 0.295, 'drive': 0.242, 'motor': 0.227, 'ability': 0.227, 'next': 0.176, 'illness': 0.176, 'diminish': 0.176}}}
CodePudding user response:
Create list of tuples by flatten dictonary in list comprehension first and then pass to DataFrame constructor:
L = [(a, k, v) for a, b in zip(df['TopicID'], df['keywords']) for k, v in b.items()]
df_final = pd.DataFrame(L, columns=['TopicID','Keyword','Value'])
print (df_final)
TopicID Keyword Value
0 797 licence 0.529
1 797 chapter 0.462
2 797 explains 0.263
3 797 visitor 0.244
4 797 resident 0.220
5 797 applying 0.205
6 797 privileges 0.199
7 797 graduated 0.188
8 797 tests 0.184
9 797 licensing 0.180
10 798 emotional 0.352
11 798 mental 0.327
12 798 state 0.309
13 798 operate 0.295
14 798 drive 0.242
15 798 motor 0.227
16 798 ability 0.227
17 798 next 0.176
18 798 illness 0.176
19 798 diminish 0.176