The actual question
Given the data following data:
library(dplyr)
df <- tibble(v1 = 1:6, cond = c(1, 0, 1, 1, 0, 1))
## # A tibble: 6 × 2
## v1 cond
## <int> <dbl>
## 1 1 1
## 2 2 0
## 3 3 1
## 4 4 1
## 5 5 0
## 6 6 1
I want to calculate a mixture of cumulative sum and cumulative product. If cond = 1 calcutate the sum of current v1 and the results of the preceding calculations. If cond = 0 calculate the product of current v1 and the results of the preceeding calcultions.
The desired result should look like this:
## # A tibble: 6 × 3
## v1 cond cum_prodsum
## <int> <dbl> <int>
## 1 1 1 1
## 2 2 0 2
## 3 3 1 5
## 4 4 1 9
## 5 5 0 45
## 6 6 1 51
In SPSS this is the code I would use:
COMPUTE cum_prodsum = 0.
IF($casenum = 1 & cond = 1) cum_prodsum = v1.
IF($casenum > 1 & cond = 0) cum_prodsum = lag(cum_prodsum) * v1
IF($casenum > 1 & cond = 1) cum_prodsum = lag(cum_prodsum) v1.
But how can this be done in R?
Sounds like a silly task that noone never ever would need to do? Yeah, it probably is. But think of it as a simple example for a whole group of problems where the calculation of the current row depends on the calculation results of the preceding rows.
Some information for (former) SPSS users working with R (not part of the question)
When I used to work with SPSS I often used a combination of the IF
and LAG command in order to do some common tasks, such as slicing the
data and keeping only the first row of each group. When I started
working with R, I quickly learned, that for those common task, R usually
comes with some handy functions, so that there is no need to program own
routines with the lag function. And even for not so common task, a
little research often leads to solution without iterating through the
data.
In the end the situations where I think “Well, I know how to do it in
SPSS with the LAG command. But how could I do it in R?” are very very
rare. The dplyr package from R comes with a lag function but it
works different, so that the naive approach substituting SPSS-LAG by the
R-lag would not work.
Difference between LAG from SPSS and dplyr:lag from R
Let’ say you have the following data with just one column:
library(dplyr)
df <- tibble(v1 = 1:6)
## # A tibble: 6 × 1
## v1
## <int>
## 1 1
## 2 2
## 3 3
## 4 4
## 5 5
## 6 6
When computing a new a variable in SPSS with lag, SPSS processes cases sequentially from top to bottom. The results from the calculation of the preceding rows can be used for computing the current row.
COMPUTE lagsum_spss = v1.
IF ($casenum > 1) lagsum_spss = lagsum_spss LAG(lagsum_spss).
Which results in:
## # A tibble: 6 × 2
## v1 lagsum_spss
## <int> <int>
## 1 1 1
## 2 2 3
## 3 3 6
## 4 4 10
## 5 5 15
## 6 6 21
The dplyr::lag function on the other hand, is a vectorised function,
which applies the calculations to all elements in a vector
simultaneously. So when I try mimicking the SPSS behavior in R with the
mutate and lag functions I get a different result:
df %>%
mutate(lagsum_r = v1,
lagsum_r = lagsum_r lag(lagsum_r, default = 0))
## # A tibble: 6 × 3
## v1 lagsum_spss lagsum_r
## <int> <int> <dbl>
## 1 1 1 1
## 2 2 3 3
## 3 3 6 5
## 4 4 10 7
## 5 5 15 9
## 6 6 21 11
The fourth row, for example is calculates as this:
lagsum_spss[4] = 4 6 and lagsum_r[4] = 4 3.
So how can we reproduce this calculation in R? Well in this case it is quite simple:
df %>%
mutate(cumsum = cumsum(v1))
## # A tibble: 6 × 3
## v1 lagsum_spss cumsum
## <int> <int> <int>
## 1 1 1 1
## 2 2 3 3
## 3 3 6 6
## 4 4 10 10
## 5 5 15 15
## 6 6 21 21
See, no need for lag, this time.
OK OK, but what if I want to sum only values from cases that meet a certain condition, a conditional cumsum if you say so?
Example data set:
df <- tibble(v1 = 1:6, cond = c(1, 0, 1, 1, 0, 1))
df
## # A tibble: 6 × 2
## v1 cond
## <int> <dbl>
## 1 1 1
## 2 2 0
## 3 3 1
## 4 4 1
## 5 5 0
## 6 6 1
The SPSS code would look like this:
COMPUTE cond_cumsum = 0.
IF($casenum = 1 & cond = 1) cond_cumsum = v1.
IF($casenum > 1 & cond = 0) cond_cumsum = lag(cond_cumsum).
IF($casenum > 1 & cond = 1) cond_cumsum = lag(cond_cumsum) v1.
So how this can be done in R? Well the solution is also pretty easy:
df %>%
mutate(cond_cumsum = cumsum(v1 * cond))
## # A tibble: 6 × 3
## v1 cond cond_cumsum
## <int> <dbl> <dbl>
## 1 1 1 1
## 2 2 0 1
## 3 3 1 4
## 4 4 1 8
## 5 5 0 8
## 6 6 1 14
For a task, where I think it is unavoidable to to iterate through the data rows, see the question above.
CodePudding user response:
So what we want to do is basicly this: Start with the two first elements
of a vector as input, do stuff with it, use that outcome as the first
input and the next vector element as the second input, do the same stuff
again, use that outcome as new first input … and so on. If you heard
about the Reduce (base R) or reduce and accumulate (purrr)
functions, this may sound familiar.
This is an illustration from the purrr Cheat Sheet of how the accumulate function works:
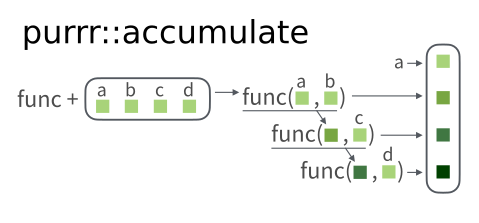
Lets first think about the function that we want to apply:
- first we want to check if
condis 0 or 1 - if
condis 1 then sumv1from the current row with the outcome from the preceeding step. - if not, then multiply
v1from the current row with the outcome from the preceeding step.
So we program this function in R:
function(last_result, i){ # i stands for the row index.
if(condition[i]) last_result v1[i]
else last_result * v1[i]
}
Now lets think about the first row, since we have no “last_result”
which we could throw into that function. Following the idea of a
cumulative sum, and a cumulative product. The value should be
cumsum(v1[1]) if cond[1] is 1 or prodsum(v1[1]) if not. In both cases
these functions will return v1[1]. So this is our initial value for
the first row.
OK now, lets put this together for the accumulate function from the purrr package:
library(purrr)
df %>%
mutate(
cum_prodsum = accumulate(
.x = row_number()[-1], # apply the funtion on all rows, except the first one.
.init = v1[1], # initial value for the first row.
.f = function(last_result, i) {
if (cond[i]) last_result v1[i]
else last_result * v1[i]
}
))
## # A tibble: 6 × 3
## v1 cond cum_prodsum
## <int> <dbl> <int>
## 1 1 1 1
## 2 2 0 2
## 3 3 1 5
## 4 4 1 9
## 5 5 0 45
## 6 6 1 51
And this is it. For similar type of problems where the calculation of a value depends on the calculations of the preceeding values, just adjust the function within the accumulate command to your needs.
CodePudding user response:
library(dplyr)
df <-
tibble(v1 = as.numeric(1:6), v2 = c(1, 0, 1, 1, 0, 1))
df %>%
mutate(output = case_when(v2 == 1 ~ cumsum(v1),
v2 == 0 ~ cumprod(v1)))