I have a df like this:
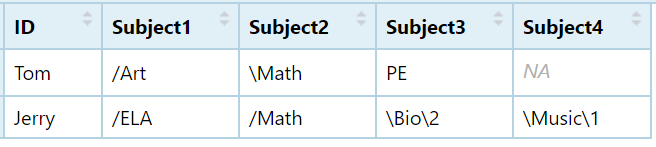
I want to clean it up by two method:
gsubthe subject 1-4 if it started with\or/to""; or- change all
/to\, and add\to the one that is not start with\.
Is it a way to do this using mutate(across(everything(),...) or any other way?
I would like to know how to achieve both methods if it is possible. Thanks.
The ideal output will looks like this:

sample data:
df<- structure(list(ID = c("Tom", "Jerry"), Subject1 = c("/Art", "/ELA"
), Subject2 = c("\\Math", "/Math"), Subject3 = c("PE", "\\Bio\\2"
), Subject4 = c(NA, "\\Music\\1")), row.names = c(NA, -2L), class = c("tbl_df",
"tbl", "data.frame"))
CodePudding user response:
We may match any character that are not a letter from the start (^) and remove it with str_remove
library(dplyr)
library(stringr)
df %>%
mutate(across(starts_with("Subject"),
~ str_remove(.x, "^[^[:alpha:]] ")))
-output
# A tibble: 2 × 5
ID Subject1 Subject2 Subject3 Subject4
<chr> <chr> <chr> <chr> <chr>
1 Tom Art Math "PE" <NA>
2 Jerry ELA Math "Bio\\2" "Music\\1"
Or escape the \\
df %>%
mutate(across(starts_with("Subject"), ~ str_remove(.x, "^(/|\\\\)")))
# A tibble: 2 × 5
ID Subject1 Subject2 Subject3 Subject4
<chr> <chr> <chr> <chr> <chr>
1 Tom Art Math "PE" <NA>
2 Jerry ELA Math "Bio\\2" "Music\\1"
or can also be
df %>%
mutate(across(starts_with("Subject"), ~ str_remove(.x, "^[/\\\\]")))
# A tibble: 2 × 5
ID Subject1 Subject2 Subject3 Subject4
<chr> <chr> <chr> <chr> <chr>
1 Tom Art Math "PE" <NA>
2 Jerry ELA Math "Bio\\2" "Music\\1"
For the second case, it would be to use str_replace
df %>%
mutate(across(starts_with("Subject"),
~ str_replace(str_replace(.x, "^\\\\", "/"), "^([A-Z])", "/\\1")))
# A tibble: 2 × 5
ID Subject1 Subject2 Subject3 Subject4
<chr> <chr> <chr> <chr> <chr>
1 Tom /Art /Math "/PE" <NA>
2 Jerry /ELA /Math "/Bio\\2" "/Music\\1"