In the first chapter of Text Mining with R Silge & Robinson propose the following code to produce the plots shown in 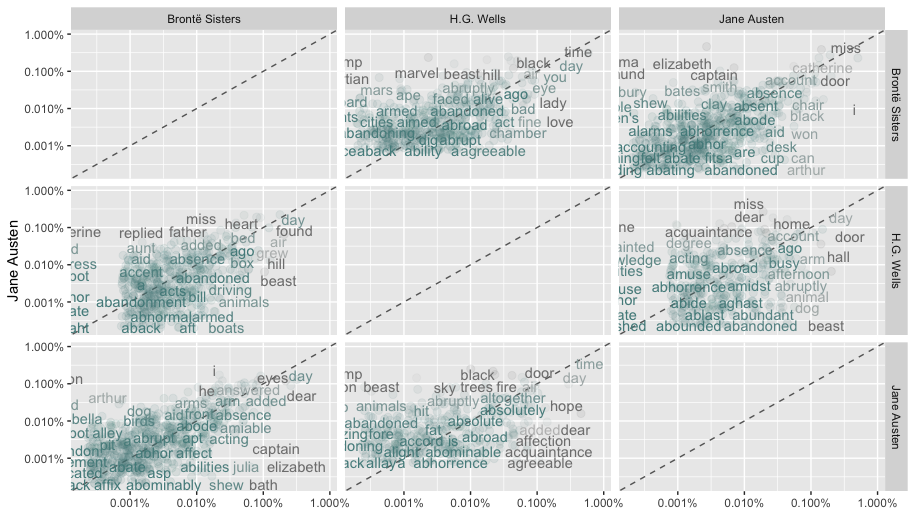
You might consider adding a slice_sample(n = 10000) %>% or similar in between the prep and the ggplot in case it's too slow for your taste. In my experience ggplot2 starts to get too sluggish for my taste when n > 10k; in this case the combined data has 171k points so it's real slow.