I am trying to make a function to spot the columns with "100" in the header and replace the values in these columns with NaN depending on multiple criteria. For instance let's say I have a df where I want to replace all numbers that are above 100 or below 0 with NaN values :
I start with this dataframe

import pandas as pd
data = {'first_100': ['25', '1568200', '5'],
'second_column': ['first_value', 'second_value', 'third_value'],
'third_100':['89', '9', '589'],
'fourth_column':['first_value', 'second_value', 'third_value'],
}
df = pd.DataFrame(data)
print (df)
expected output:
CodePudding user response:
here is one way :
for col in df.columns:
if "100" in col:
df.loc[(df[col] > 100) | (df[col] < 0), col] = np.NAN
print(df)
output :
>>
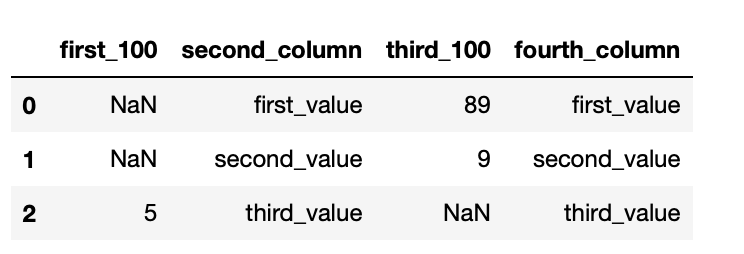
first_100 second_column third_100 fourth_column
0 NaN first_value 89 first_value
1 NaN second_value 9 second_value
2 5 third_value NaN third_value