I'm working on Pyspark python. I downloaded a sample csv file from Kaggle (Covid Live.csv) and the data from the table is as follows when opened in visual code
(Raw CSV data only partial data)
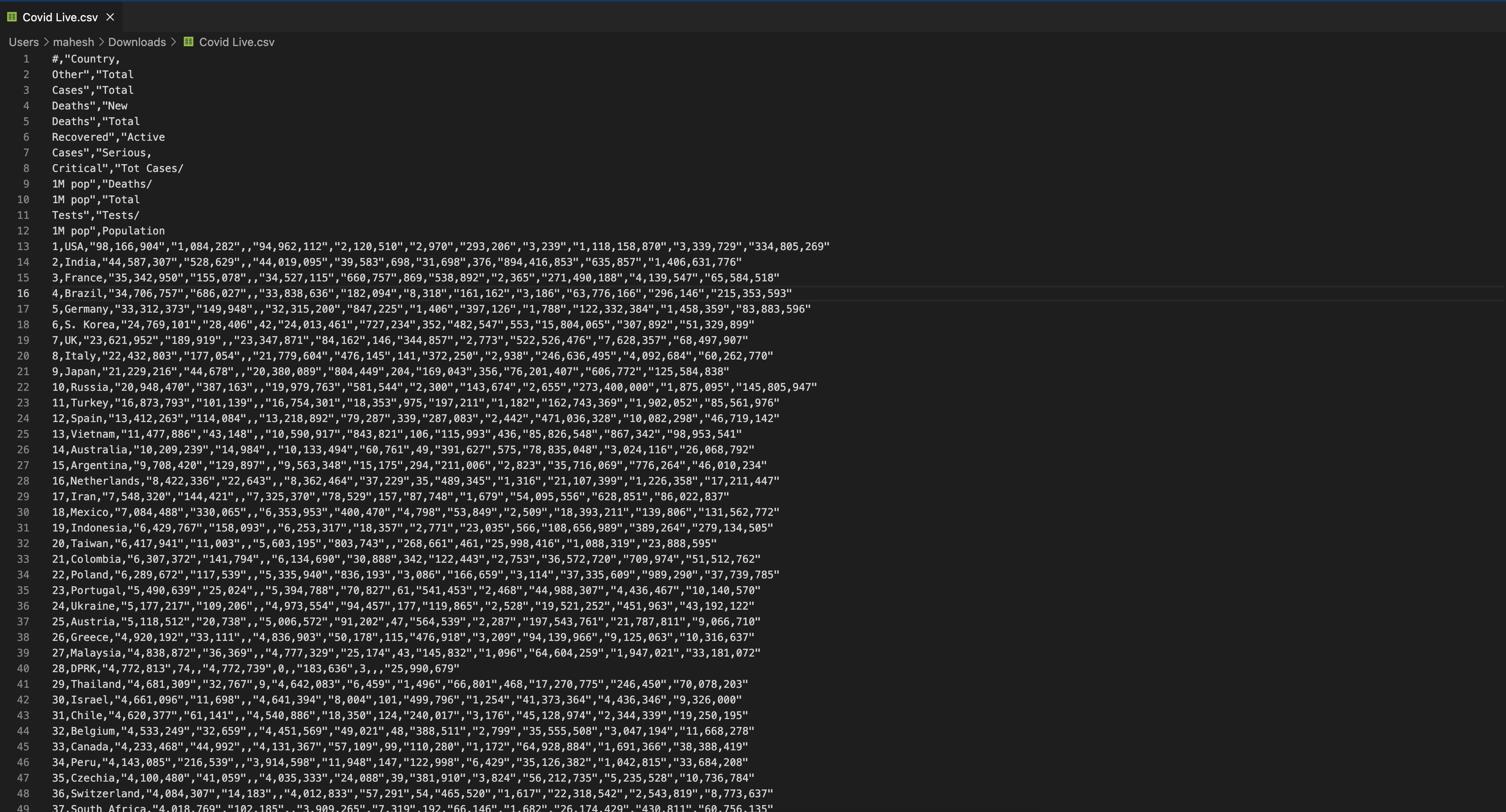
#,"Country,
Other","Total
Cases","Total
Deaths","New
Deaths","Total
Recovered","Active
Cases","Serious,
Critical","Tot Cases/
1M pop","Deaths/
1M pop","Total
Tests","Tests/
1M pop",Population
1,USA,"98,166,904","1,084,282",,"94,962,112","2,120,510","2,970","293,206","3,239","1,118,158,870","3,339,729","334,805,269"
2,India,"44,587,307","528,629",,"44,019,095","39,583",698,"31,698",376,"894,416,853","635,857","1,406,631,776"........
The problem i'm facing here, the column names are also being displayed as records in pyspark databricks console when executed with below code
from pyspark.sql.types import *
df1 = spark.read.format("csv") \
.option("inferschema", "true") \
.option("header", "true") \
.load("dbfs:/FileStore/shared_uploads/[email protected]/Covid_Live.csv") \
.select("*")
Spark Jobs -->
df1:pyspark.sql.dataframe.DataFrame
#:string
Country,:string
As can be observed above , spark is detecting only two columns # and Country but not aware that 'Total Cases', 'Total Deaths' . . are also columns
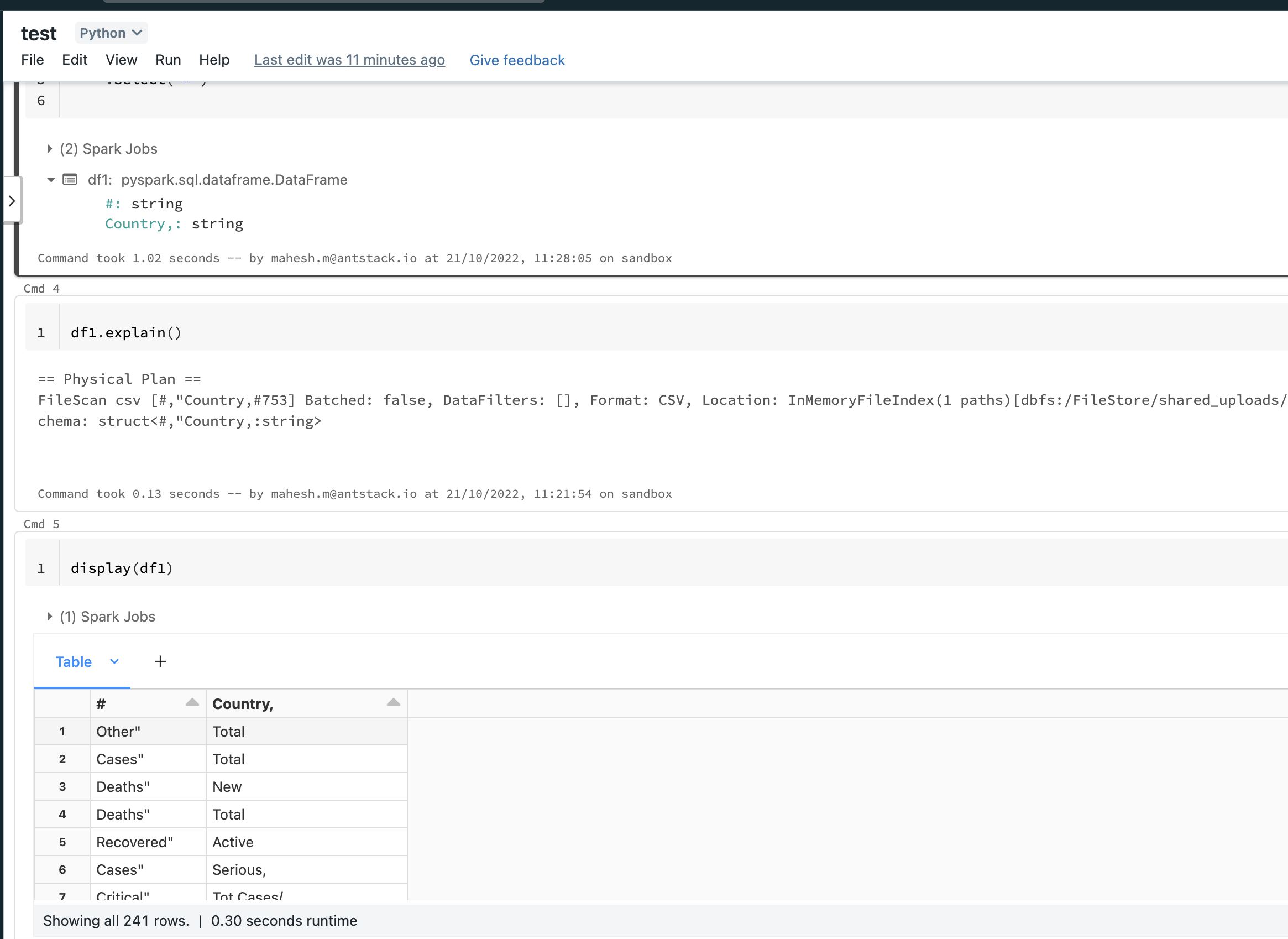
How do i tackle this malformation ?
CodePudding user response:
Few ways to go about this.
- Fix the header in the csv before reading (should be on a single line). Also pay attention to quoting and escape settings.
- Read in PySpark with manually provided schema and filter out the bad lines.
- Read using pandas, skip the first 12 lines. Add proper column names, convert to PySpark dataframe.
CodePudding user response:
So , the solution is pretty simple and does not require you to 'edit' the data manually or anything of those sorts.
I just had to add .option("multiLine","true") \ and the data is displaying as desired!