I am trying to generate 6 boxplots displaying Fish Abundances of 3 different sites (Elalab, Malafo, Cafine), displayed for each site between 2 seasons (dry / rainy) separately using faced_grid.
I want to add Tukey HSD results (in letters) on each single boxplot, but when I try, I always get the results of the dry season displayed (same values on rainy season boxplots).
Can someone help me out?
This is my code:
dput(Indices)
structure(list(
Abundance = c(110526, 56899, 9128, 45940, 32167,
19450, 11242, 125706, 66552, 17584, 87568, 109561, 97820, 140529,
172520, 157244, 30543, 46264, 36053, 92031, 60372, 82231, 36612,
106511, 128589, 127603, 89800, 129918, 140791, 162289, 27749,
13723, 50577, 116099, 117761, 94721, 76399, 90391, 84503)
Site = structure(c(3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 1L,1L,
1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 2L, 2L, 2L, 2L,
2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L),
levels = c("Elalab", "Malafo", "Cafine"), class = "factor"),
Season = structure(c(1L, 1L, 1L, 1L, 2L, 2L, 2L, 2L, 2L, 2L, 1L,
1L, 1L, 1L, 1L, 1L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 1L, 1L, 1L,
1L, 1L, 1L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L),
levels = c("Dry", "Rainy"), class = "factor"),
class = "data.frame")
str(Indices)
anova <- aov(Abundance ~ Site, data = Indices)
summary(anova)
tukey <- TukeyHSD(anova)
print(tukey)
cld <- multcompLetters4(anova, tukey)
print(cld)
Tk <- group_by(Indices, Site) %>%
summarise(mean=mean(Abundance), quant = quantile(Abundance, probs = 0.75)) %>%
arrange(desc(mean))
cld <- as.data.frame.list(cld$Site)
Tk$cld <- cld$Letters
print(Tk)
#creating the boxplots for each site, separated for each season
bp1<-ggplot(Indices, aes(Site, Abundance))
geom_boxplot(aes(fill = Season, alpha = Site))
theme_test()
facet_grid( ~ Season)
scale_alpha_discrete(range = c(0.3, 0.9),
guide = guide_legend(override.aes = list(fill = "black")))
scale_fill_manual(values = c("#E08B00", "steelblue3"))
stat_compare_means(method = "anova", label.y = -0.3) # Add global p-value
geom_text(data = Tk, aes(x = Site, y = quant, label = cld), size = 4)
bp1
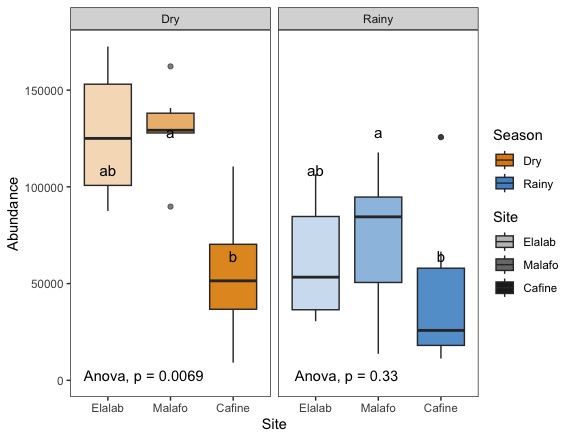
CodePudding user response:
You need to group by Season too when building the labels for the plot (the Tk) data frame:
library(tidyverse)
library(multcompView)
library(ggpubr)
anova <- aov(Abundance ~ Site, data = Indices)
tukey <- TukeyHSD(anova)
cld <- multcompLetters4(anova, tukey)
Tk <- group_by(Indices, Season, Site) %>%
summarise(mean = mean(Abundance),
quant = quantile(Abundance, probs = 0.75)) %>%
mutate(cld = cld$Site$Letters[Site])
ggplot(Indices, aes(Site, Abundance))
geom_boxplot(aes(fill = Season, alpha = Site))
theme_test()
facet_grid( ~ Season)
scale_alpha_discrete(range = c(0.3, 0.9))
scale_fill_manual(values = c("#E08B00", "steelblue3"))
stat_compare_means(method = "anova", label.y = -0.3)
geom_text(data = Tk, aes(x = Site, y = quant, label = cld), size = 4,
nudge_y = -4000)
guides(alpha = guide_legend(override.aes = list(fill = "black")))
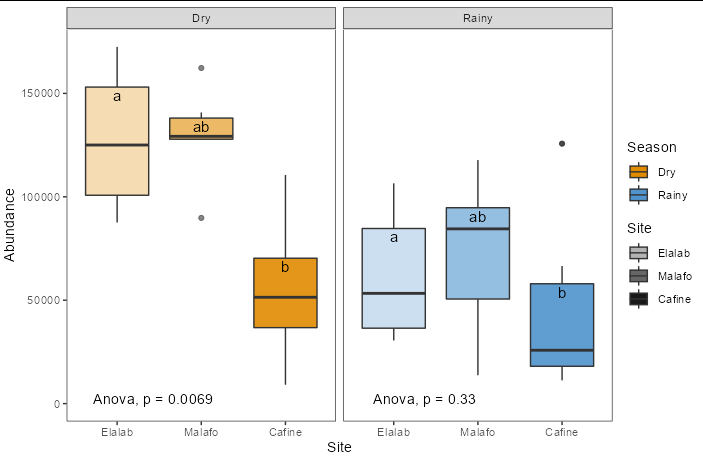
CodePudding user response:
All that was missing was the inclusion of the Season factor in the ANOVA and of course its interaction with Site. In addition, this allows us to study the interactions in Tukey's test. Basically, what you were asking for was to be able to group the observations according to homogeneous groups taking into account both factors simultaneously: Site and Season.
library(tidyverse)
library(multcompView)
library(ggpubr)
# This is a 2-way ANOVA with interactions Site * Season
anova <- aov(Abundance ~ Site * Season, data = Indices)
summary(anova)
tukey <- TukeyHSD(anova)
print(tukey)
cld <- multcompLetters4(anova, tukey) # includes interactions!
print(cld)
Indices<-as.data.frame(Indices)
Tk <- group_by(Indices, Site,Season) %>%
summarise(mean=mean(Abundance), quant = quantile(Abundance, probs = 0.75)) %>%
arrange(desc(mean))
cld <- as.data.frame.list(cld$`Site:Season`)
Tk$cld <- cld$Letters
print(Tk)
#creating the boxplots for each site, separated for each season
bp1<-ggplot(Indices, aes(Site, Abundance))
geom_boxplot(aes(fill = Season, alpha = Site))
theme_test()
facet_grid( ~ Season)
scale_alpha_discrete(range = c(0.3, 0.9),
guide = guide_legend(override.aes = list(fill = "black")))
scale_fill_manual(values = c("#E08B00", "steelblue3"))
stat_compare_means(method = "anova", label.y = -0.3) # Add global p-value
geom_text(data = Tk, aes(x = Site, y = quant*1.7, label = cld), size = 5)
bp1
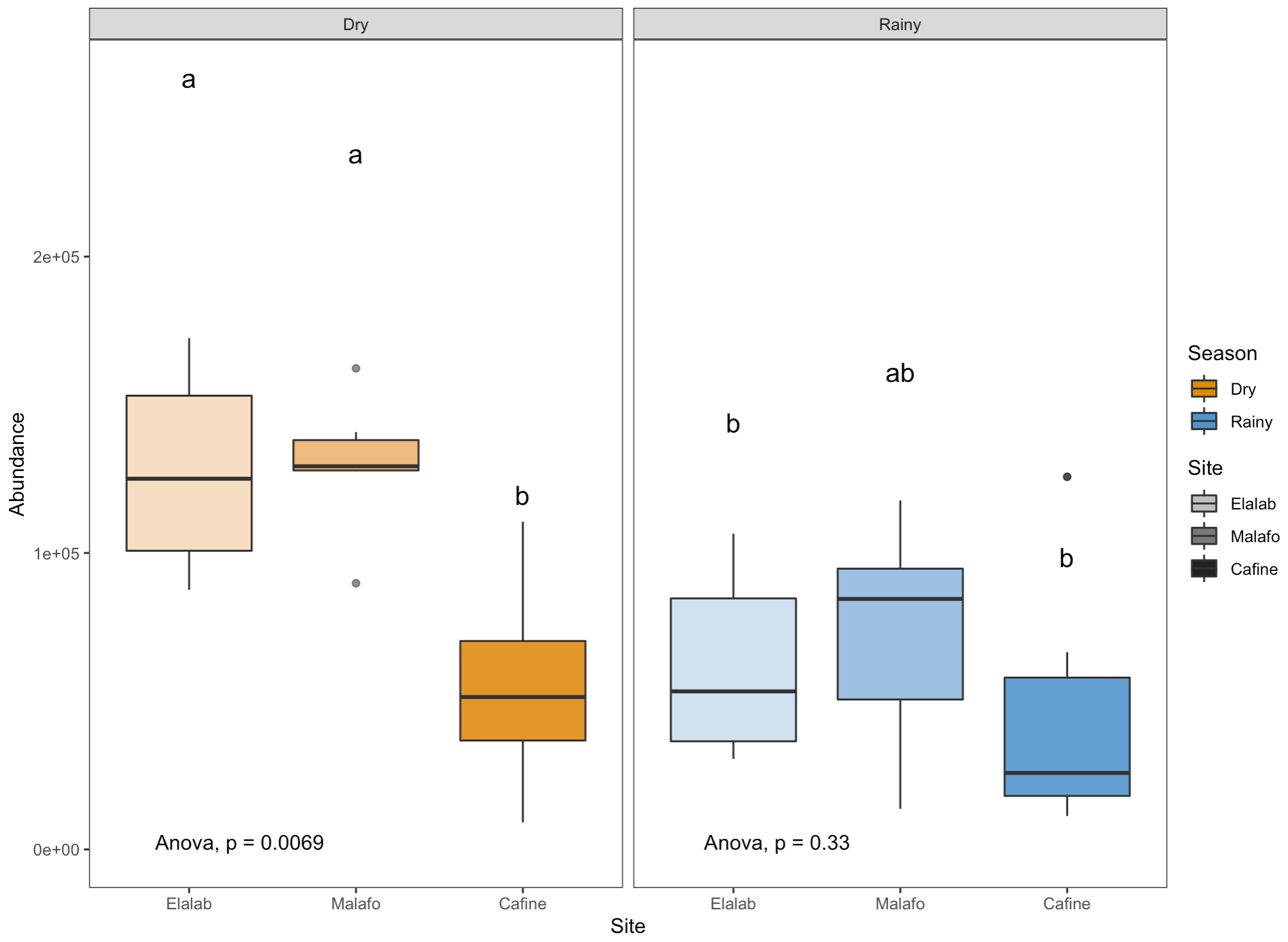
However, you should be careful with the interpretation of these homogeneous subsets, they may include combined levels that you have no interest in comparing (e.g. "Cafine Dry is similar to Elalab Rainy"). Think about whether you need to tell this grouping or whether you need to tell something else about the interaction: What happens in rainy seasons at each site? Is the pattern the same or is it different? These questions will help you to tell the results of the interaction. The letters should serve as a "pointer" for a clear explanation of a paragraph.