I am relatively new to Vega Lite and have a question that I'm hoping is fairly straightforward.
I have a parameter array called myExtent that I've hard coded to [0, 6]. I'd like to be able to set the upper value of the array based on the data. Here, because the 4th row has "flag" = 1, I'd like to set the upper limit to the "score" for that row, or 6. So,
{"name": "myExtent", "value": [0, (value of score for the row in the dataset where flag = 1)]}
Is something like this possible, or is there an alternative way I should be thinking about this?
`
{"$schema": "https://vega.github.io/schema/vega-lite/v5.json",
"params": [
{"name": "myExtent", "value": [0, 6]}
],
"data": {
"values": [
{"game": 1, "score": 2, "flag": 0},
{"game": 2, "score": 4, "flag": 0},
{"game": 3, "score": 5, "flag": 0},
{"game": 4, "score": 6, "flag": 1},
{"game": 5, "score": 9, "flag": 0}
]
},
"mark": {"type": "area"},
"transform": [
{
"density": "score",
"extent": {"signal": "myExtent"}
}
],
"encoding": {
"x": {"field": "value", "type": "quantitative", "scale": {"domain": [0, 10]}},
"y": {"field": "density", "type": "quantitative"}
}
}
`
Just to get started, I have tried something like this:
`
"params": [
{"name": "upperLimit", "value": 6},
{"name": "myExtent", "value": [0, {"expr": "upperLimit"}]}
],
`
However, that (a) doesn't seem to work and (b) doesn't (yet) get at how to set the upperLimit parameter to the score for row 4.
CodePudding user response:
What is the logic behind providing a dynamic extent and not letting it calculate from the whole dataset? This is quite difficult to do in VL and you probably need Vega. Having said that, if you can add a column with the max extent repeated for the whole dataset, it can be achieved. I have repurposed the flag column here to do what you want.
{
"$schema": "https://vega.github.io/schema/vega-lite/v5.json",
"params": [
{"name": "val", "expr": "data('source_0')[0]['flag']"},
{"name": "myExtent", "expr": "[0,val]"}
],
"data": {
"values": [
{"game": 1, "score": 2, "flag": 6},
{"game": 2, "score": 4, "flag": 6},
{"game": 3, "score": 5, "flag": 6},
{"game": 4, "score": 6, "flag": 6},
{"game": 5, "score": 9, "flag": 6}
]
},
"mark": {"type": "area"},
"transform": [
{"calculate": "datum.flag==1?datum.score:0", "as": "new"},
{"joinaggregate": [{"op": "max", "field": "new", "as": "test"}]},
{"density": "score", "extent": {"signal": "myExtent"}}
],
"encoding": {
"x": {
"field": "value",
"type": "quantitative",
"scale": {"domain": [0, 10]}
},
"y": {"field": "density", "type": "quantitative"}
}
}
CodePudding user response:
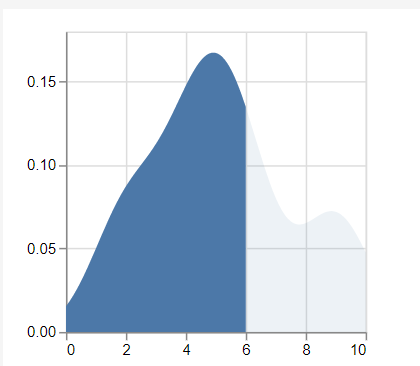
With David Bacci's excellent guidance (thanks again!), I was able to build a solution that seems to accomplish what I was after. By flagging one of the rows with flag = 1, the user can see a density graph that helps them understand the percentile rank of the score in question (in this case, they're interested in game 4):
{"$schema": "https://vega.github.io/schema/vega-lite/v5.json",
"params": [
{"name": "upperLimit", "expr": "data('data_1')[0]['maxScore']"},
{"name": "myExtent", "expr": "[0,upperLimit]"}
],
"data": {
"name": "rawData",
"values": [
{"game": 1, "score": 2, "flag": 0},
{"game": 2, "score": 4, "flag": 0},
{"game": 3, "score": 5, "flag": 0},
{"game": 4, "score": 6, "flag": 1},
{"game": 5, "score": 9, "flag": 0}
]
},
"layer": [
{ // first layer to perform the transform without density
"mark": {"type": "area", "opacity": 0.1},
"transform": [
{"calculate": "datum.flag==1?datum.score:0", "as": "myScore"},
{"joinaggregate": [{"op": "max", "field": "myScore", "as": "maxScore"}]}
],
"encoding": {
"x": {"field": "game", "type": "quantitative", "scale": {"domain": [0, 10]}, "title": null}
}
},
{ // second layer to show whole sample with low opacity
"mark": {"type": "area", "opacity": 0.1},
"transform": [{"density": "score", "extent": [0, 10]}],
"encoding": {
"x": {
"field": "value",
"type": "quantitative"
},
"y": {"field": "density", "type": "quantitative", "title": null}
}
},
{ // third layer to show partial sample based on flagged row
"mark": {"type": "area"},
"transform": [
{"density": "score", "extent": {"signal": "myExtent"}}
],
"encoding": {
"x": {
"field": "value",
"type": "quantitative"
},
"y": {"field": "density", "type": "quantitative"}
}
}
]
}
This approach creates 3 layers, the first with a transform that David suggested to find the score in question, but without the density function. The second layer has a density function that shows the whole sample and the third layer shows just the part of the sample of interest. The parameters then refer not to the raw data source, but to data_1, which is the output of the first transform. Thanks to the online Vega Lite editor for helping me figure that bit out. But, especially thanks to David Bacci for pointing me in the right direction!