I have a dataframe (cells) that it looks like this (it has more rows):
| ID | Time(min) | Cell1 | Cell2 | Cell3 | Cell4 | Cell5 | Cell6 | Cell7 | |
|---|---|---|---|---|---|---|---|---|---|
| AA001 | 0 | 10.57 | 77.28 | 14.11 | 15.12 | 1.56 | 95.83 | 3.41 | |
| AA001 | 30 | 12.99 | 77.96 | 15.01 | 15.35 | 1.60 | 96.02 | 3.37 | |
| AA001 | 90 | 11.41 | 79.85 | 16.69 | 19.65 | 1.28 | 92.14 | 6.01 | |
| AA001 | 180 | 15.89 | 75.11 | 12.48 | 11.95 | 1.34 | 95.90 | 3.69 | |
| AA001 | 360 | 10.16 | 83.67 | 19.51 | 14.68 | 1.09 | 70.80 | 26.21 | |
| AA003 | 0 | 12.34 | 81.16 | 17.77 | 17.49 | 1.83 | 84.94 | 13.31 | |
| AA006 | 0 | 21.71 | 71.24 | 7.67 | 11.43 | 1.56 | 90.03 | 7.62 | |
| AA006 | 7 | 15.23 | 78.81 | 15.60 | 12.19 | 2.23 | 93.38 | 3.4 |
I have grouped by the variables ID and Time, because I would like to see the "evolution" of each cell for each sample:
inmune %>%
group_by(PID, Time)
So, I have performed a scatter plot, but it's a mess with so many lines connected to each point.
Also I tried transform in a long-data format:
df2<- melt(cells, id = "Time")
But it results in a table with 3 variables (Time, cells, values) so I miss the ID.
The idea is to represent the difference of the values for each time, grouped by the ID.
But any suggestion about other type of graphs more suitable for this kind of data is more than welcome. Thanks!!
CodePudding user response:
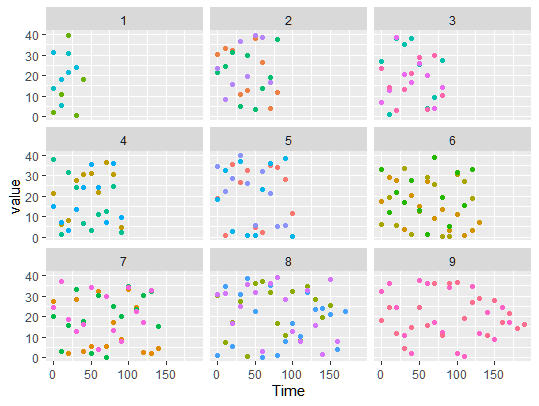
Here are two options separating the ID's in facets.
Dummy data:
df = tibble(ID = sample(letters, 300, TRUE),
value = runif(300, 0, 40))
df = df %>%
group_by(ID) %>%
mutate(Time = seq(0, by = 10, length = n())) %>%
arrange(ID)
Obs: if your problem was the visualization of lots of ID's, it would've been better if you posted your whole data using dput()
One facet for each group:
df %>%
ggplot(aes(Time, value))
geom_point()
facet_wrap(vars(ID)) #try using scales = "free_x"

Grouping several ID's in each facet:
You can choose different concepts to group some ID's together, I choose the number of times they had data for, as that seems to vary in your data.
k = 9 #number of groups, change it as you please
facets = df %>%
group_by(ID) %>%
summarise(n = n(), .groups = "drop") %>%
mutate(facets = ntile(n, k))
df = df %>% mutate(facets = facets$facets[match(ID, facets$ID)])
df %>%
ggplot(aes(Time, value, color = ID))
geom_point()
facet_wrap(vars(facets)) #try using scales = "free_x"
theme(legend.position = "none")
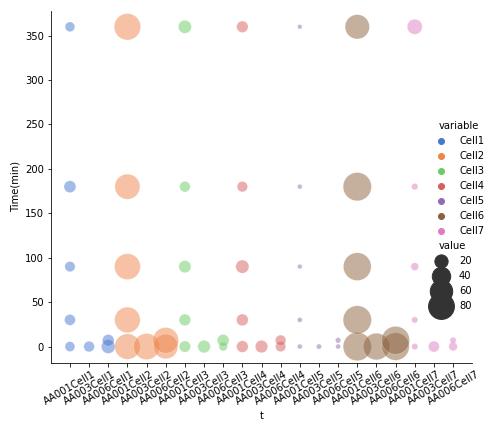
CodePudding user response:
I would guess you'd like to see something like this:
import seaborn as sns
df1 = df.melt(id_vars=["ID", "Time(min)"], value_vars=["Cell1", "Cell2", "Cell3", "Cell4", "Cell5", "Cell6", "Cell7"])
df1["t"] = df1["ID"] df1["variable"]
res = sns.relplot(x="t", y="Time(min)", hue="variable", size="value",
sizes=(20, 800), alpha=.5, palette="muted",
height=6, data = df1)
res.set_xticklabels(rotation=30)