I have a dataset in excel with multiple columns that contain one specific set of data that is randomly distributed within these columns. The data looks like this:
Col1 Col2 Col3 Col4 Col5 Col6
Data 34 NA NA NA NA
NA NA Data 32 NA NA
NA NA NA NA Data 12
NA Data 89 NA NA NA
I want to get all the Data fields into one column named data, so the data set looks like this (the NA columns are not important for now, I have this issue with several fields, so I will need to replicate the solution for other fields as well):
Data
34
32
12
89
As I am currently working in excel, an easy solution there would be great, however, I will move to R at some point, so a solution in R would also be welcomed!
Thank you very much and sorry for the cryptic description.
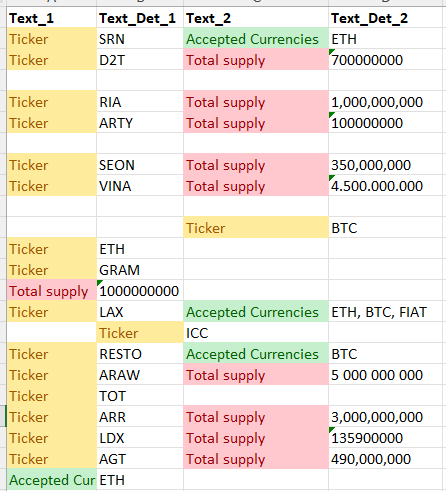
Edit: Here is a picture of my real data - in this example I want a column named "Total supply", one named "Ticker" and one named "Accepted Currencies", with the respective data (following the named cell) in the correct column.
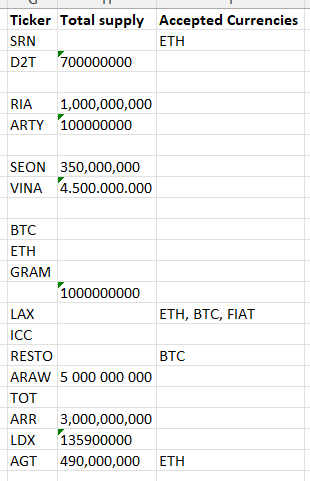
The output should look like this:
CodePudding user response:
If your data is in a matrix called mat, the following code extracts the desired values into a vector:
apply(mat, 1L, \(row) row[which(row == 'Data') 1L])
# [1] "34" "32" "12" "89"
This assumes that the data is correctly formatted. Any divergence will yield unexpected results.
It’s also possible to do this without apply using vectorised functions but the resulting code is a bit longer:
ind = which(mat == 'Data', arr.ind = TRUE)
ord = order(ind[, 1L])
mat[cbind(seq_along(ord), ind[ord, 2L] 1L)]
CodePudding user response:
Try:
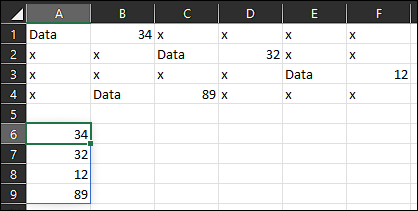
Formula used in A6:
=TOCOL(IF(A1:E4="Data",B1:F4,NA()),3)
Or, a bit more dynamic:
=LET(a,A1:F4,TOCOL(IF(DROP(a,,-1)="Data",DROP(a,,1),NA()),3))
EDIT: Updated answer based on new information;
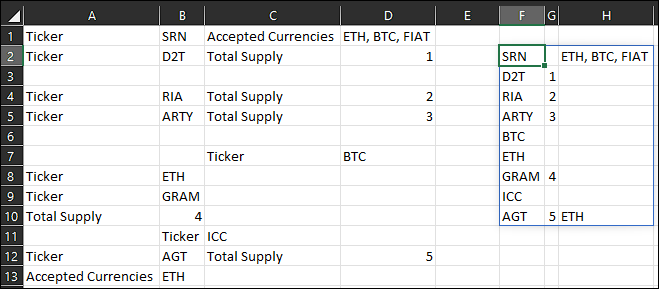
Formula in F2:
=LET(a,TOCOL(A1:D13,3),IFERROR(DROP(REDUCE(EXPAND(0,,3),SEQUENCE(ROWS(a-1)),LAMBDA(x,y,LET(b,INDEX(a,y 1),c,FILTER(x,NOT(ISERROR(TAKE(x,,1)))),SWITCH(INDEX(a,y),"Ticker",VSTACK(c,b),"Total Supply",VSTACK(DROP(c,-1),HSTACK(TOROW(TAKE(c,-1),3),b)),"Accepted Currencies",VSTACK(DROP(c,-1),HSTACK(TAKE(c,-1,2),b)),c)))),1),""))
CodePudding user response:
With the example df from below, you could do:
df[] <- lapply(df, as.character)
df <- data.frame(Data = c(t(df)), stringsAsFactors = FALSE)
subset(df, ave(Data, cumsum(is.na(Data)), FUN = length) > 1L & Data != 'Data')
Output:
Data
2 34
10 32
18 12
21 89
This approach would capture multiple consecutive occurrences of values. You haven't specified whether (and how) potential NA values occurring after Data should be captured - that would require a modification (e.g. you could capture all the values occurring after each appearance of Data in case they contain at least one non-NA, or it could be you just wanted to capture single NA in case the whole vector afterwards is empty but we've nevertheless Data, etc.).
Data:
df <- read.table(
text = 'Col1 Col2 Col3 Col4 Col5 Col6
Data 34 NA NA NA NA
NA NA Data 32 NA NA
NA NA NA NA Data 12
NA Data 89 NA NA NA', header = TRUE
)