I have:
df=pd.DataFrame({'col1':['x','x','x','x','x','y','y','y','y','y','y','y'],
'value':[0,0,0,0,0,0,0,0,0,0,0,0]})
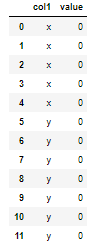
I would like:

the value column to increase by a constant value depending on the number of times it appears in col1. for each occurrence of x, it increases by 100, and for each occurrence of y it increases by 150
CodePudding user response:
We'll start by getting the cumulative count for each item in col1:
df['value'] = df.groupby('col1').cumcount()
Next, we need to apply the multiplication by item:
multiples = {
'x': 100,
'y': 150
}
for col, value in multiples.items():
index = df['col1'] == col
df.loc[index,'value'] *= value
Giving the final result:
col1 value
0 x 0
1 x 100
2 x 200
3 x 300
4 x 400
5 y 0
6 y 150
7 y 300
8 y 450
9 y 600
10 y 750
11 y 900
CodePudding user response:
EDIT: SNygard beat me to it, but I try to present a solution that makes use of pandas' broadcasting architecture and bypasses the inneficiencies of iteration.
It is said that when you iterate over a dataframe's rows, you lose pandas' efficiency by using it to a purpose it was not intended for.
Here's how I would do it:
import pandas as pd
col1_to_value_hash = {
'x': 100,
'y': 150
}
df = pd.DataFrame({
'col1': ['x', 'x', 'x', 'x', 'x', 'y', 'y', 'y', 'y', 'y', 'y', 'y'],
'value': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
})
cumcount = df.groupby('col1').cumcount()
df['value'] = cumcount * df['col1'].apply(lambda x: col1_to_value_hash[x])