I want to match dictionary values with an entry in a csv dataframe column and put the corresponding dictionary key in a new column.
I have a csv dataframe with a Link and six columns with numbers. I have a dictionary with Sites and many Links.
import pandas as pd
# reproducible data
data = {'Link': ['A1', 'B2', 'X7', '8G'],
'Town1': [0.124052256, 0.939612252, 0.861338299, 0.981016558],
'Town2': [0.605572804, 0.561737172, 0.479567258, 0.476371433],
'Town3': [0.41687511, 0.321543551, 0.1243927, 0.097894068],
'Town4': [0.068305033, 0.280721459, 0.600126058,0.93097328]}
# Create DataFrame
df = pd.DataFrame(data)
# Print the output.
df
#Dictionary
d = {'Sample1': '[A1, 6H, 8J, A3, 4L]', 'Sample2': '[X7, 8G, 4R]', 'Sample3': '[B2, V6, 8U]' }
###What I want is to find where the dictionary value and the entry in the 'Link' column match and make a new column on the same csv file with the dictionary key.
This is what I tried and it returned None in the new column
def get_key(node):
for node in df['Link']:
if node in d.values():
return d.keys()
df['Parent'] = df['Link'].apply(lambda x: get_key(x))
df
Output like this:
Last thing I want is to .groupby.sum() the df['Parent'] column and make a final pivot table of the Samples and the sum in each of the 'Town' columns.
Final table example:
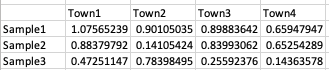
CodePudding user response:
def matcher(find_this_value):
your_dict = {'Sample1': ['A1', '6H', '8J', 'A3', '4L'], 'Sample2': ['X7', '8G', '4R'], 'Sample3': ['B2', 'V6', '8U']}
for key, values in your_dict.items():
for value in values:
if find_this_value in value:
return key
df['dict_key'] = df['Link'].apply(matcher)