I have a dataset that look like
df = pd.DataFrame({'ID': [1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2],
'DATE_11': ['1/1/2011','1/2/2015', '1/3/2015','1/4/2012','1/5/2011','1/6/2011','1/7/2011','1/8/2009',
'1/9/2016','1/2/2015','1/3/2015','1/4/2015','1/5/2015','1/6/1998','1/7/2011'],
'Column_1': ['A','B','S','A','B','S','A','A','C','A','A','A','A','A','A'],
'DATE_22': ['1/1/2015','1/2/2013', '1/3/2012','1/4/2015','1/5/2015','1/6/2015','1/7/2015','1/8/2015',
'1/9/2016','1/2/2015','1/3/2015','1/4/2015','1/5/2015',np.nan,'1/7/2011'],
'Column_2': ['A','A','A','A','B','B','A','A','B','S','A','A','A','A','A'],
'DATE_3': ['1/1/2016','1/2/2015', '1/3/2015','1/4/2015','1/5/2015','1/6/2015','1/7/2015','1/8/2015',
'1/1/2016','1/2/2011','1/3/2001','1/4/2002','1/5/2006','1/6/1998','1/7/2011'],
'Column_S': ['A','A','B','S','B','B','A','B','S','A','A','E','D','A','C']})
Here, I need to get minimum of 3 dates and get column value and column name that fulfills the condition
Here Column_1--DATE_11, Column_2--DATE_22 and DATE_3-- Column_S are 3 pairs.
I got the minimum of DATE_11, DATE_22, DATE_3 by
df[['DATE_11','DATE_22','DATE_3']] = df[['DATE_11','DATE_22','DATE_3']].apply(pd.to_datetime, format='%m/%d/%Y')
df['min_result'] = df[['DATE_11','DATE_22','DATE_3']].min(axis = 1)
But how do I get Column Value and column name. For example, I need to get "Column_1", "A" as 2 column value since minimum comes from DATE_11 and it is paired with Column_1. For last 2 row, all value are same or 2 values are same and 1 is null, we can just leave both column as null so np.nan, np.nan as the result.
Can you please at least direct me to some function/module that can do this? I am completely lost at how I can do this.
Expected Result :
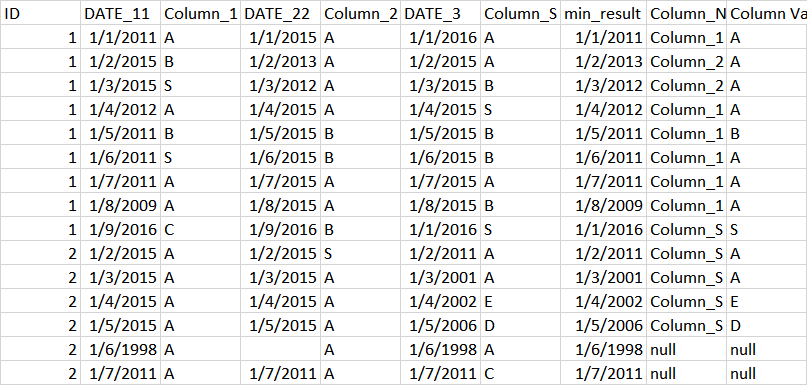 SOrry I dont know how to create tabular here so adding picture
SOrry I dont know how to create tabular here so adding picture
Thanks, Sam
CodePudding user response:
divide df and concat
df1 = (pd.concat([df.iloc[:, 1:3].rename(columns={'DATE_11':'DATE'}),
df.iloc[:, 3:5].rename(columns={'DATE_22':'DATE'}),
df.iloc[:, 5:7].rename(columns={'DATE_3':'DATE'})])
.sort_values('DATE'))
df1.head(5)
DATE Column_1 Column_2 Column_S
0 1/1/2011 A NaN NaN
0 1/1/2015 NaN A NaN
0 1/1/2016 NaN NaN A
8 1/1/2016 NaN NaN S
9 1/2/2011 NaN NaN A
(df1.groupby(level=0).head(1)
.set_index('DATE', append=True).stack().reset_index([1, 2]).sort_index()
.set_axis(['min_result', 'column_N', 'column value'], axis=1))
result:
min_result column_N column value
0 1/1/2011 Column_1 A
1 1/2/2013 Column_2 A
2 1/3/2012 Column_2 A
3 1/4/2012 Column_1 A
4 1/5/2011 Column_1 B
5 1/6/2011 Column_1 S
6 1/7/2011 Column_1 A
7 1/8/2009 Column_1 A
8 1/1/2016 Column_S S
9 1/2/2011 Column_S A
10 1/3/2001 Column_S A
11 1/4/2002 Column_S E
12 1/5/2006 Column_S D
13 1/6/1998 Column_1 A
14 1/7/2011 Column_S C
if you want, make value of row 13 to null
and you can concat df1 & result