I have 2 dataframes which look something like this.
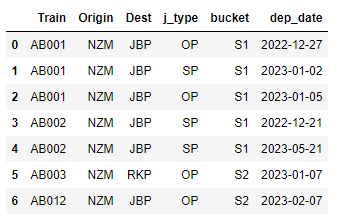
Train Departure Details (data_df)
pd.DataFrame(columns=['Train', 'Origin', 'Dest', 'j_type', 'bucket', 'dep_date'],
data = [['AB001', 'NZM', 'JBP', 'OP', 'S1', '2022-12-27'],
['AB001', 'NZM', 'JBP', 'SP', 'S1', '2023-01-02'],
['AB001', 'NZM', 'JBP', 'OP', 'S1', '2023-01-05'],
['AB002', 'NZM', 'JBP', 'SP', 'S1', '2022-12-21'],
['AB002', 'NZM', 'JBP', 'SP', 'S1', '2023-05-21'],
['AB003', 'NZM', 'RKP', 'OP', 'S2', '2023-01-07'],
['AB012', 'NZM', 'JBP', 'OP', 'S2', '2023-02-07'],
]
)
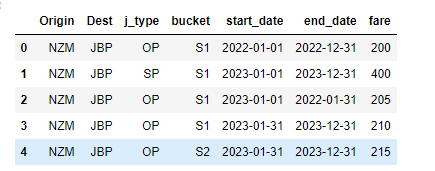
Fares Dataframe (fares_df)
pd.DataFrame(columns=['Origin', 'Dest', 'j_type', 'bucket', 'start_date', 'end_date', 'fare'],
data = [['NZM', 'JBP', 'OP', 'S1', '2022-01-01', '2022-12-31', 200],
['NZM', 'JBP', 'SP', 'S1', '2023-01-01', '2023-12-31', 400],
['NZM', 'JBP', 'OP', 'S1', '2023-01-01', '2022-01-31', 205],
['NZM', 'JBP', 'OP', 'S1', '2023-01-31', '2023-12-31', 210],
['NZM', 'JBP', 'OP', 'S2', '2023-01-31', '2023-12-31', 215]]
)
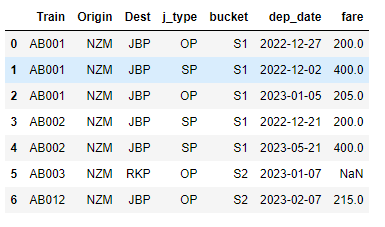
I need to merge these 2 Datframes such that fares are applied based on correct dep_date that falls between start_date & end_date and also correct origin, destination, j_type & bucket columns
Expected Result
What I have tried:
ranges = fares[['start_date', 'end_date']].drop_duplicates().reset_index(drop=True)
# Get array of dep_date, start_dates, and end_dates
dep_dates = data_df['dep_date'].values
low_date = ranges['start_date'].values
high_date = ranges['end_date'].values
# Generate arrays for which set of date ranges the dep_date falls between
i, j = np.where((dep_dates[:, None] >= low_date) & (dep_dates[:, None] <= high_date))
# Add date range columns to data_df:
data_df.reset_index(inplace=True)
data_df.loc[i, 'fare_start_date'] = np.column_stack([ranges['start_date'].values[j]])
data_df.loc[i, 'fare_end_date'] = np.column_stack([ranges['end_date'].values[j]])
data_df.merge(
fares_df,
left_on=['Origin', 'Dest',
'bucket', 'j_type',
'fare_start_date', 'fare_end_date'],
right_on=['Origin', 'Dest',
'bucket', 'j_type',
'start_date', 'end_date'],
how='left')
However this does not give me the correct result after merge.
CodePudding user response:
df = data_df.rename(columns={'dep_date':'start_date'}) # rename is better than too many right_on, left_on
df1 = pd.merge_asof(df.sort_values('start_date'), fares_df.sort_values('start_date'), by=fares_df.columns[:4].tolist(), on='start_date')
df1['fare'] = df1['fare'].where(df1['start_date'] < df1['end_date']) # chk out of end_date. of course example has not this case.
df1
Train Origin Dest j_type bucket start_date end_date fare
0 AB002 NZM JBP SP S1 2022-12-21 NaT NaN
1 AB001 NZM JBP OP S1 2022-12-27 2022-12-31 200.0
2 AB001 NZM JBP SP S1 2023-01-02 2023-12-31 400.0
3 AB001 NZM JBP OP S1 2023-01-05 2023-01-31 205.0
4 AB003 NZM RKP OP S2 2023-01-07 NaT NaN
5 AB012 NZM JBP OP S2 2023-02-07 2023-12-31 215.0
6 AB002 NZM JBP SP S1 2023-05-21 2023-12-31 400.0
merge df1 to df for order
out = df.merge(df1.drop('end_date', axis=1), how='left').rename(columns={'start_date':'dep_date'})
out
Train Origin Dest j_type bucket dep_date fare
0 AB001 NZM JBP OP S1 2022-12-27 200.0
1 AB001 NZM JBP SP S1 2023-01-02 400.0
2 AB001 NZM JBP OP S1 2023-01-05 205.0
3 AB002 NZM JBP SP S1 2022-12-21 NaN
4 AB002 NZM JBP SP S1 2023-05-21 400.0
5 AB003 NZM RKP OP S2 2023-01-07 NaN
6 AB012 NZM JBP OP S2 2023-02-07 215.0
CodePudding user response:
at the end after data_df.merge, I guess you should select only rows where the dep_date falls between start_date and end_date like this:
merged_df = data_df.merge(fares_df,
left_on=['Origin', 'Dest', 'bucket', 'j_type', 'fare_start_date', 'fare_end_date'],
right_on=['Origin', 'Dest', 'bucket', 'j_type', 'start_date', 'end_date'],
how='left')
merged_df = merged_df[(merged_df['dep_date'] >= merged_df['start_date']) & (merged_df['dep_date'] <= merged_df['end_date'])]