I will ask my question with a small dataframe, but the real one is 1000s of lines.
ID Name #Required
123 New York 5
234 Boston 6
345 Miami 2
345 Dallas 7
I need the to the number of columns equals to the max in the '#Required' column and fill them in like this:
ID Name #Required J01 J02 J03 J04 J05 J06 J07
123 New York 5 123W001 123W002 123W003 123W004 123W005 "blank" "blank"
234 Boston 6 234W001 234W002 234W003 234W005 234W005 234W006 "blank"
345 Miami 2 345W001 345W002 "blank" "blank" "blank" "blank" "blank"
399 Dallas 7 399W001 399W002 399W003 399W004 399W005 399W006 399W007
The number of values for each row depends on the number in the "#Required" column. with a "W" after "ID" and also I need to know how to handle the values if the number in "#Required" is greater than 10, because then the entry should be 123W010, only 1 leading 0.
ID Name #Required J01 J02 J03 J04 J05 J06 J07
123 New York 5 123W001 123W002 123W003 123W004 123W005 "blank" "blank"
234 Boston 6 234W001 234W002 234W003 234W005 234W005 234W006 "blank"
345 Miami 2 345W001 345W002 "blank" "blank" "blank" "blank" "blank"
399 Dallas 7 399W001 399W002 399W003 399W004 399W005 399W006 399W007
CodePudding user response:
Interesting problem. Here is a pandas way of doing this. Explanation in the second section -
# Your dummy dataset
df = pd.DataFrame({'ID': [123, 234, 345, 399],
'Name': ['New York', 'Boston', 'Miami', 'Dallas'],
'#Required': [5, 6, 2, 7]})
# Creating list of the required values per row
new_lists = df.apply(lambda x: [str(x['ID']) 'W' format(i, '03d') for i in range(1,x['#Required'] 1)], 1)
# Converting the list to individual columns with nan values
new_cols = new_lists.apply(pd.Series)
# Creating column names
col_names = ['J' format(i, '02d') for i in range(1,len(new_cols.columns) 1)]
# Adding new columns to original dataframe
df[col_names] = new_cols
# Replacing nan values via "blank"
df = df.fillna('"blank"')
df

Explanation
- The
format(x, '03d')gives you are 3 length string formed with a digit, so for1 -> 001and for10 -> 010 - You can form the required strings for each row using
str(x['ID']) 'W' format(i, '03d')whereiis the range of digits from 1 to the value in the#Requiredcolumn. - The
[str(x['ID']) 'W' format(i, '03d') for i in range(1,x['#Required'] 1)]is a list comprehension that gives you the result as a list. So, if you print thenew_lists, it will look like this -
print(new_lists)
0 [123W001, 123W002, 123W003, 123W004, 123W005]
1 [234W001, 234W002, 234W003, 234W004, 234W005, ...
2 [345W001, 345W002]
3 [399W001, 399W002, 399W003, 399W004, 399W005, ...
dtype: object
- Next, with the
.apply(pd.Series)you get the lists, expanded to individual columns, and the smaller length lists fill up the rest of the columns withNanvalues. Printing thenew_colsat this stage results in this -
print(new_cols)
0 1 2 3 4 5 6
0 123W001 123W002 123W003 123W004 123W005 NaN NaN
1 234W001 234W002 234W003 234W004 234W005 234W006 NaN
2 345W001 345W002 NaN NaN NaN NaN NaN
3 399W001 399W002 399W003 399W004 399W005 399W006 399W007
- Now to create the column names, we again use just a simple list comprehension, with the range of the number of columns in the
new_colsand leverage the previously usedformat(x, '02d')but this time for 2 digits.
print(col_names)
['J01', 'J02', 'J03', 'J04', 'J05', 'J06', 'J07']
Finally you add the
new_colsas new columns to the original dataframedfby usingdf[col_names] = new_colsAnd, last but not the least, you replace the
nanvalues with"blank"as your question show, using a simpledf.fillna('"blank"')
Bonus
Here is how the code works if you have double digit integers in #Required column, such as 10 or 12
# Sample dataframe with 12 and 10 values in #Required
df = df = pd.DataFrame({'ID': [123, 234, 345, 345],
'Name': ['New', 'Boston', 'Miami', 'Dallas'],
'#Required': [5, 10, 2, 12]})
new_lists = df.apply(lambda x: [str(x['ID']) 'W' format(i, '03d') for i in range(1,x['#Required'] 1)], 1)
new_cols = new_lists.apply(pd.Series)
col_names = ['J' format(i, '02d') for i in range(1,len(new_cols.columns) 1)]
df[col_names] = new_cols
df = df.fillna('"blank"')
df

Notice that the column names went from J01 to J12 and the values for the new columns for the rows with #Required values like 10 or 12 look like 234W010 or 399W012.
EDIT
For 1-2 digit ids you can modify the code with the same format logic as before.
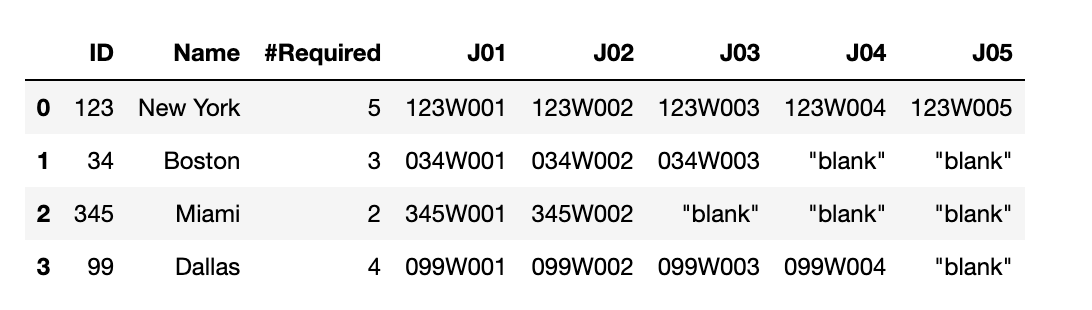
# Sample dataframe 2 digit IDs
df = df = pd.DataFrame({'ID': [123, 34, 345, 99],
'Name': ['New York', 'Boston', 'Miami', 'Dallas'],
'#Required': [5, 3, 2, 4]})
new_lists = df.apply(lambda x: [format(x['ID'], '03d') 'W' format(i, '03d') for i in range(1,x['#Required'] 1)], 1)
new_cols = new_lists.apply(pd.Series)
col_names = ['J' format(i, '02d') for i in range(1,len(new_cols.columns) 1)]
df[col_names] = new_cols
df = df.fillna('"blank"')
df
CodePudding user response:
Proposed code
import pandas as pd
# Your dummy dataset
df = pd.DataFrame({'ID': [123, 234, 345, 399],
'Name': ['New York', 'Boston', 'Miami', 'Dallas'],
'#Required': [5, 6, 2, 7]})
m = max(df['#Required']) # Maximum number in '#Required'
lm = len(str(m)) # length of the maximum number in '#Required'
how_to_fill = {'J%s'%str(n).zfill(1 lm):['%sW%s'%(i,str(n).zfill(2 lm)) if n <= r else 'Blank' for i,r in zip(df['ID'], df['#Required'])] for n in range(1, m 1)}
df = df.join(pd.DataFrame(how_to_fill)).set_index('ID')
print(df)
Result :
Name Required J01 J02 ... J04 J05 J06 J07
ID ...
123 New York 5 123W001 123W002 ... 123W004 123W005 Blank Blank
234 Boston 6 234W001 234W002 ... 234W004 234W005 234W006 Blank
345 Miami 2 345W001 345W002 ... Blank Blank Blank Blank
399 Dallas 7 399W001 399W002 ... 399W004 399W005 399W006 399W007
Note :
I suggest you the use of np.nan with import numpy as np instead of "Blank"