I have a short procedure in PL/SQL which uses UTL_FILE package to create and then write to a .txt file. Tab is saved in its own variable (v_delimiter), declared as varchar2(5), with a value of chr(9). The header is saved as a string, concatenated with the v_delimiter and then written to a file. After that, the rest of the data from an explicit cursor is also written to a file, line by line. In the end, when I open the txt file, there are unequal widths between some of the strings which make up a header. There are also unequal widths between some of the data from the cursor inside a final .txt file and I guess that shouldn't be since I am using one and the same delimiter (tab) to create a header and to create a string from a cursor.
I am using UTL_FILE.put_line_nchar function to write a Unicode line to a file. I tried without declaring a delimiter as a variable, using literally chr(9) when concatenating and it is always the same result. I am out of ideas why is this happening in the final txt file.
v_file_handle UTL_FILE.file_type ;
v_output_path VARCHAR2 (100) := '/Path/to/File' ;
v_file_header VARCHAR2 (32767) ;
v_delimiter VARCHAR2 (5) := chr(9) ;
v_file_handle := UTL_FILE.fopen_nchar (v_output_path,'string_1' || TO_CHAR (SYSDATE, 'dd_mm_yyyy') || '.txt','w', 32767); -- opening
v_file_header :='claimFileIdentifier'|| v_delimiter || 'claimFileOpenedDate'
|| v_delimiter|| 'claimStatus'|| v_delimiter|| 'claimStatusDate'|| v_delimiter|| 'incidentDateTime'|| v_delimiter|| 'incidentPlace'|| v_delimiter|| 'calculationType' ... -- header
UTL_FILE.put_line_nchar ( v_file_handle, v_file_header ) ; --writing header to a file
FOR rec IN cursor_candidates --iterating over a cursor
LOOP
UTL_FILE.put_line_nchar (
v_file_handle,
rec.claimFileIdentifier
|| v_delimiter
|| rec.claimFileOpenedDate
|| v_delimiter
|| rec.claimStatus
|| v_delimiter
|| rec.claimStatusDate
|| v_delimiter
|| rec.incidentDateTime
|| v_delimiter
|| rec.incidentPlace
|| v_delimiter ... ) ; -- writing cursor rows to a file
END LOOP ;
UTL_FILE.fclose ( v_file_handle );
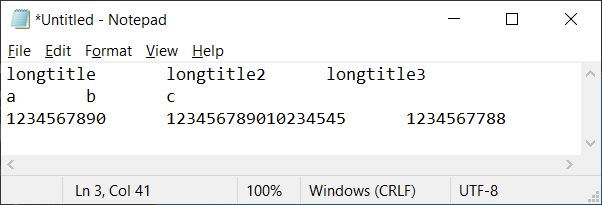
And the columns are unequal across the rows.
However, if I display the same data in an editor that supports TSV files (such as Notepad ) then it displays the same output with equal widths for the columns across the rows:
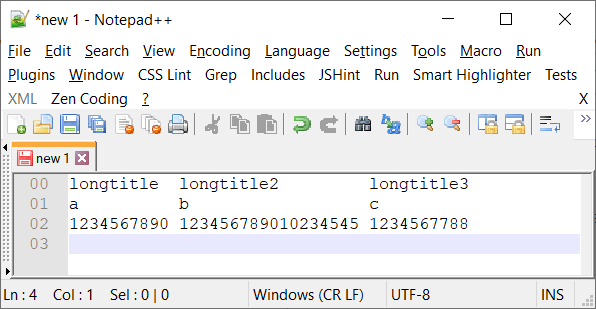
Importing the data into a spreadsheet application (such as Excel or OpenOffice), then the TSV is separated into cells and the output is:
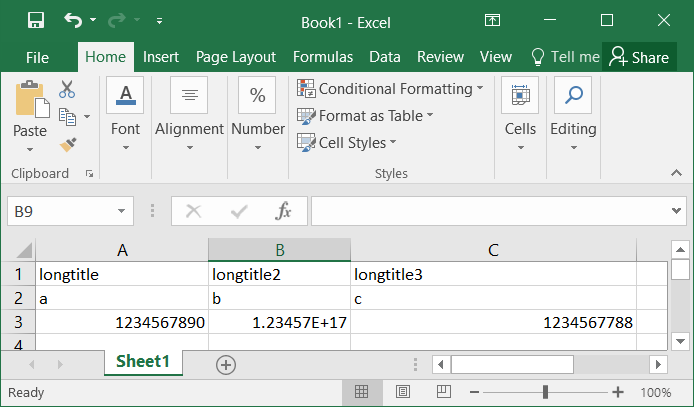
And, again, the information is split into columns.
Do not change how you are outputting the file; instead, find a better way of viewing the output file with an application that supports formatting tab-separated values.