I have two columns and I want to reshape the table for a cross-count. How may I achieve this through Pandas?
data = {'fruit':["orange, apple, banana", "orange, apple, banana", "apple, banana", "orange, apple, banana", "others"],
'places':["New York, London, Boston", "New York, Manchester", "Tokyo", "Hong Kong, Boston", "London"]}
df = pd.DataFrame(data)
fruit place
0 orange, apple, banana New York, London, Boston
1 orange, apple, banana New York, Manchester
2 apple, banana Tokyo
3 orange, apple, banana Hong Kong, Boston
4 others London
Expected output:
New York London Boston Hong Kong Manchester Tokyo
orange 2 2 2 1 1 0
apple 2 1 2 1 1 1
banana 2 1 2 1 1 1
others 0 1 0 0 0 0
CodePudding user response:
You can use 
df3 = df2.explode("fruits").explode("places")
df3.head()
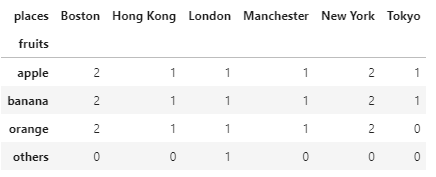
pd.pivot_table(df3, index="fruits", columns="places", aggfunc=len, fill_value=0)
# Or the less generic alternative:
# pd.crosstab(df3["fruits"], df3["places"])
It is left as an exercise to the reader to bring all those steps together :)
CodePudding user response:
One approach is to create cartesian product using itertools.product and then use pd.Series.explode and pd.crosstab
from itertools import product
f = lambda x: list(product(x['places'].split(','), x['fruit'].split(',')))
df['fruit_places'] = df.apply(f, axis=1)
ddf = pd.DataFrame.from_records(df['fruit_places'].explode().values, columns=['places', 'fruit'])
pd.crosstab(ddf['fruit'], ddf['places'])