Hello I'm trying to scrape some questions from a web forum
I am able to scrape questions with a
find_elements_by_xpath
it's something like this :
questions = driver.find_elements_by_xpath('//div[@]//div[@]//div[@]//p')
I made a diagram so you can understand my situation :
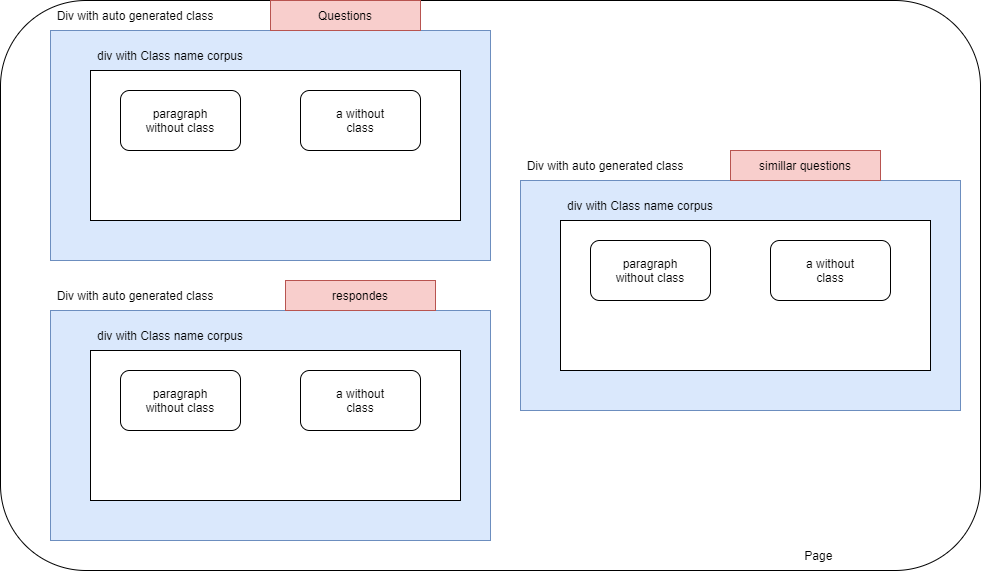
my problem is if I didn't specify the auto-generated class in the XPath it's gonna return all the values from the other divs (which I don't want )
and writing the auto-generated class manually like I did to test isn't a valid idea because I'm scraping multiple questions with multiple classes
do you guys have any ideas on how to resolve this problem ??
here is the web forum
thank you
my code :
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
import time
from fastparquet.parquet_thrift.parquet.ttypes import TimeUnit
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import pandas as pd
driver = webdriver.Chrome('/Users/ossama/Downloads/chromedriver_win32/chromedriver')
page = 1
#looping in pages
while page <= 10:
driver.get('https://forum.bouyguestelecom.fr/questions/browse?flow_state=published&order=created_at.desc&page=' str(page) '&utf8=✓&search=&with_category[]=2483')
# checking to click the pop-up cookies interfaces
if page == 1:
#waiting 10s for the pop-up to show up before accepting it
time.sleep(10)
driver.find_element_by_id('popin_tc_privacy_button_3').click()
# store all the links in a list
#question_links = driver.find_elements_by_xpath('//div[@]//a[@]')
links = driver.find_elements_by_xpath('//div[@]//a[@]')
forum_links= []
for link in links:
value = link.get_attribute("href")
print(value)
forum_links.append(value)
else:
links = driver.find_elements_by_xpath('//div[@]//a[@]')
for link in links:
value = link.get_attribute("href")
print(value)
forum_links.append(value)
q_df = pd.DataFrame(forum_links)
q_df.to_csv('forum_links.csv')
page = page 1
for link in forum_links:
driver.get(link)
#time.sleep(5)
#driver.find_element_by_id('popin_tc_privacy_button_3').click()
questions = driver.find_elements_by_xpath('//div[@]//div[@]//p')
authors = driver.find_elements_by_xpath('//div[@]//div[@]//dl[@]//dd//a')
dates = driver.find_elements_by_xpath('//div[@]//div[@]//dl[@]//dd')
questions_list = []
for question in questions:
for author in authors:
for date in dates:
questions_list.append([question.text, author.text, date.text])
print(question.text)
print(author.text)
print(date.text)
q_df = pd.DataFrame(questions_list)
q_df.to_csv('colrow.csv')
CodePudding user response:
Improved XPATH, and removed second loop.
page = 1
while page <= 10:
driver.get(
'https://forum.bouyguestelecom.fr/questions/browse?flow_state=published&order=created_at.desc&page=' str(
page) '&utf8=✓&search=&with_category[]=2483')
driver.maximize_window()
print("Page url: " driver.current_url)
time.sleep(1)
if page == 1:
AcceptButton = driver.find_element(By.ID, 'popin_tc_privacy_button_3')
AcceptButton.click()
questions = driver.find_elements(By.XPATH, '//div[@]//a[@]')
for count, item in enumerate(questions, start=1):
print(str(count) ": question detail:")
questionfount = driver.find_element(By.XPATH,
"(//div[@class='corpus']//a[@class='content_permalink'])[" str(
count) "]")
questionfount.click()
questionInPage = WebDriverWait(driver, 20).until(EC.visibility_of_element_located(
(By.XPATH, "(//p[@class='old-h1']//following::div[contains(@__uid__, "
"'dim')]//div[@class='corpus']//a["
"@class='content_permalink'])[1]")))
author = WebDriverWait(driver, 20).until(EC.visibility_of_element_located(
(By.XPATH, "(//p[@class='old-h1']//following::div[contains(@__uid__, 'dim')]//div["
"@class='corpus']//div[contains(@class, 'metadata')]//dl["
"@class='author-name']//a)[1]")))
date = WebDriverWait(driver, 20).until(EC.visibility_of_element_located(
(By.XPATH, "(//p[@class='old-h1']//following::div[contains(@__uid__, 'dim')]//div["
"@class='corpus']//div[contains(@class, 'metadata')]//dl[@class='date']//dd)[1]")))
print(questionInPage.text)
print(author.text)
print(date.text)
print(
"-----------------------------------------------------------------------------------------------------------")
driver.back()
driver.refresh()
page = page 1
driver.quit()
Output (in Console):
Page url: https://forum.bouyguestelecom.fr/questions/browse?flow_state=published&order=created_at.desc&page=1&utf8=