I've looked around and tried a bunch of different things, but cant seem to find any info on this topic.
I'm trying to scrape info from my bank (Discover) and wrote a script to do so. It returns everything fine, but is returning a "logged out" page instead of the desired homepage with my balance.
My messy code is as follows:
import requests
from bs4 import BeautifulSoup as bs
def scrapeDiscover():
URL = 'https://portal.discover.com/customersvcs/universalLogin/signin'
request_URL = 'https://portal.discover.com/customersvcs/universalLogin/signin'
HEADERS = {'User-Agent':'User-Agent: Mozilla/5.0 (Windows NT; Windows NT 6.2; en-US) WindowsPowerShell/4.0', 'Origin':'https://portal.discover.com', 'Referer':'https://portal.discover.com/customersvcs/universalLogin/ac_main'}
s = requests.session()
PAYLOAD = {
'userID' : 'username',
'password' : 'password',
'choose-card' : 'Credit Card',
'pm_fp' : 'version=-1&pm_fpua=mozilla/5.0 (x11; linux x86_64) applewebkit/537.36 (khtml, like gecko) chrome/95.0.4638.69 safari/537.36|5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36|Linux x86_64&pm_fpsc=24|1920|1080|1053&pm_fpsw=&pm_fptz=-6&pm_fpln=lang=en-US|syslang=|userlang=&pm_fpjv=0&pm_fpco=1',
'currentFormId' : 'login',
'userTypeCode' : 'C',
'rememberOption' : 'on',
}
login_req = s.post(URL, headers=HEADERS, data=PAYLOAD)
cookies = login_req.cookies
soup = bs(s.get('https://card.discover.com/cardmembersvcs/achome/homepage').text, 'html.parser')
balance = soup.text
print(balance)
scrapeDiscover()
I also looked at the post request info needed, and have it here:
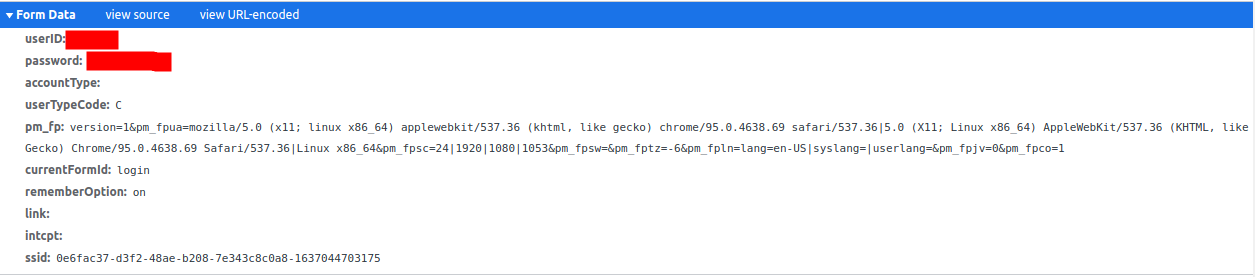
Any help or suggestions would be super appriciated! Even just a suggestion would help a ton. Thanks so much all! Let me know if more information is needed.
EDIT: Added information I imagine theres probably some missing cookie or token in the post request, but I've poured over the code many times and find anything that works when implimented, or, even if I'm implementing it correctly.
A couple things that stand out to me:
SSID: In the 'Form Data' of the post request that works, theres an 'ssid' form with a long string. However, this changes every time and I imagined that it stood for 'session ID' and that I didnt need it since my code was creating a new session.
ssid: 0433c923-6f48-4832-8d6d-b26c5b0e6d4-1637097180562
STRONGAUTHSVS: Another thing I found that stood out was this "STRONGAUTHSVS" variable (nested within the long string of cookies, both in the request and recieved headers)
STRONGAUTHSVCS=SASID=null&SATID=b081-
sectoken: Lastly, I saw the work token and I thought this could be it. A variable in the cookies with 'sectoken' as the variable name. No idea what it is though, or how I would impliment it.
sectoken=hJNQgh7EOnH1xx1skqQqftbV/kE=
With all these, I've tried my best at implimenting them into the headers in my code, but it seemed to have no effect on the output. I've attached a pastebin of the site cookies and form data captured (minus any sensitive data). If anyone has any ideas, I'd be super thankful! https://pastebin.com/PNnV6Mpw
CodePudding user response:
read this. I think, you probably need a token for your POST request, for the security reasons. If just the scraping is important, try to use selenium.
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("https://portal.discover.com/customersvcs/universalLogin/signin")
driver.maximize_window()
log_in = (
WebDriverWait(driver, 5)
.until(
EC.element_to_be_clickable(
(By.XPATH, "/html/body/div[1]/header/div[1]/div[2]/div[2]/ul/li[3]/a")
)
)
.click()
)
driver.find_element_by_xpath("//*[@id='userid']").send_keys("your_user_id")
driver.find_element_by_xpath("//*[@id='password']").send_keys("your_password")
driver.find_element_by_xpath("//*[@id='log-in-button']").click()
I got an error when I use left panel for log in.