I have the following two Queries:
WITH
T AS(
SELECT
ROW_NUMBER() OVER() AS uid,
position_geom
FROM
`bigquery-public-data.catalonian_mobile_coverage.mobile_data_2015_2017`
WHERE
date > "2017-12-26" )
SELECT
T1.uid,
T2.uid,
ST_DISTANCE(T1.position_geom, T2.position_geom) distance
FROM
T AS T1,
T AS T2
WHERE
T1.uid <> T2.uid QUALIFY ROW_NUMBER() OVER (PARTITION BY T1.uid ORDER BY ST_DISTANCE(T1.position_geom, T2.position_geom)) < 101
ORDER BY
T1.uid,
ST_DISTANCE(T1.position_geom, T2.position_geom)
AND
WITH
T AS(
SELECT
ROW_NUMBER() OVER() AS uid,
position_geom
FROM
`bigquery-public-data.catalonian_mobile_coverage.mobile_data_2015_2017`
WHERE
date > "2017-12-26" ),
T2 AS(
SELECT
T1.position_geom pointA,
T1.uid uidA,
T2.position_geom pointB,
T2.uid uidB,
ST_DISTANCE(T1.position_geom, T2.position_geom) distance
FROM
T AS T1,
T AS T2 )
SELECT
uidA,
uidB,
distance
FROM
T2
WHERE
uidA <> uidB QUALIFY ROW_NUMBER() OVER (PARTITION BY uidA ORDER BY distance) < 101
ORDER BY
uidA,
distance
Both queries give the same result, but the second goes almost twice as fast (in term of elapsed time and slot time consumed). Why is the first query not internally optimized by bigquery?
CodePudding user response:
You can see in the execution details how the queries stages are processed. The first query reads all the data that you are selecting after you join the t1 table and the t2 table, and then is fast to sort because the data is already in the temporary table, so this makes the whole sorting process faster, but when the data is being read, it makes the query execution slower.
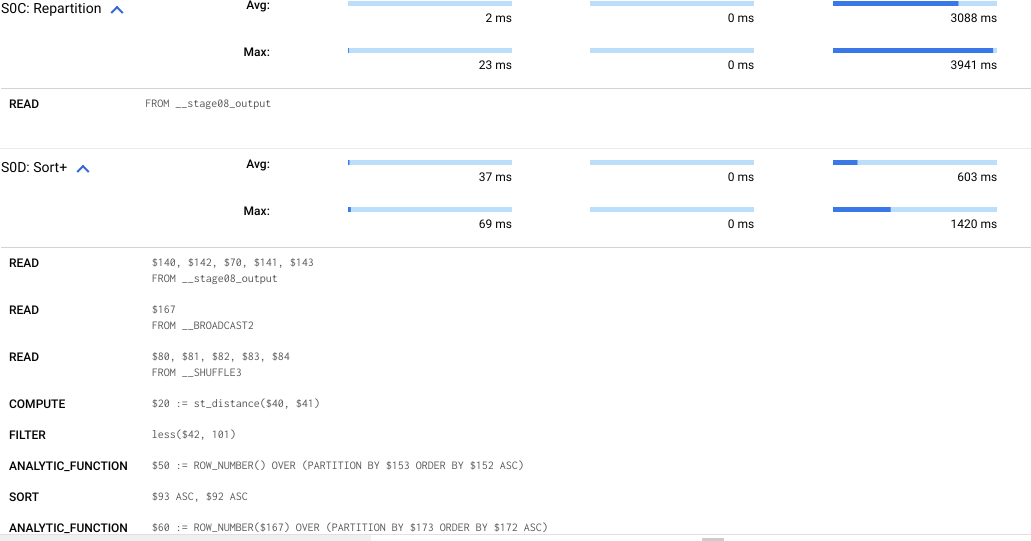
The second query is faster because it reads the data when you are in the sorting process. This means that the sorting process is slower than the first query, but you don’t have a repartition process to read the data, and this makes the query execution faster.
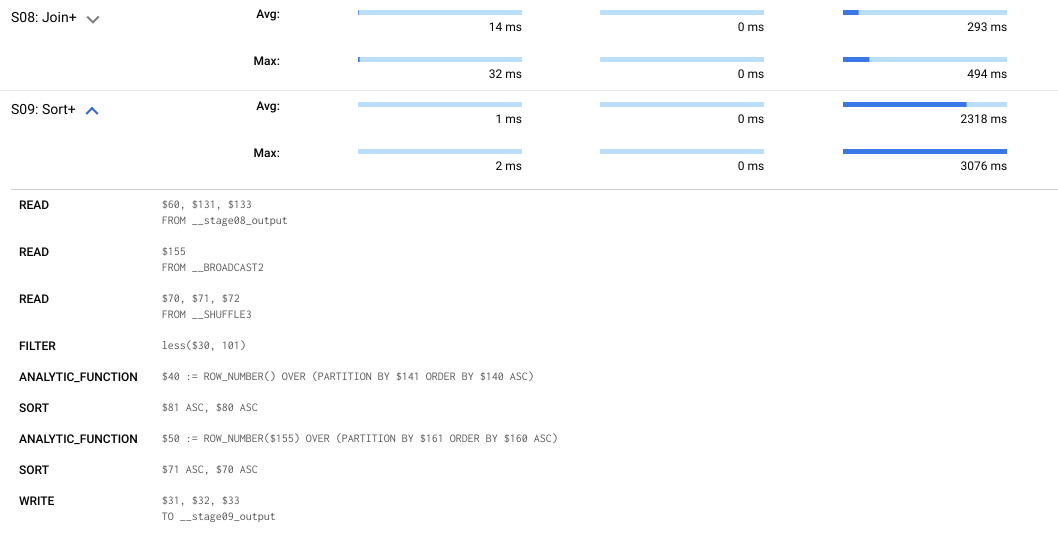
Here, the difference is how the query is written because, in the second one, you are given a subquery to distribute how the query will work, and when you read it, it is faster because there is only one reading process, which makes this consume less slot time.
CodePudding user response:
In order to give some hints, you need to precise a few elements :
- Which database are you using
- Which index(es) is(are) defined
- The number of rows in bigquery-public-data.catalonian_mobile_coverage.mobile_data_2015_2017
- Are you querying the database directly or do you go through a connector ?
Depending on the number of rows, your database engine may not use the index. Each database has - normally - a set of tools that helps to analyse queries.
mysql (should work for MariaDB too) for exemple provides the keyword EXPLAIN and ANALIZE TABLE If you have the Enterprise Edition, you can get access to Mysql query analysis
SQLServer provide SQL server query analyzer
...