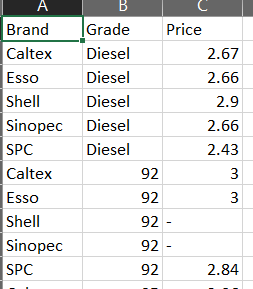
I extracted some information from a HTML table, reorganized the data and tried to output the data to a CSV file. However, I'm seeing a lot of gibberish in the 'price' column of the output CSV (see below). When I check the dataframe contents within Python, I see that the price column seems to have empty spaces/tabs and weird alignments.
Results when I print out the dataframe:
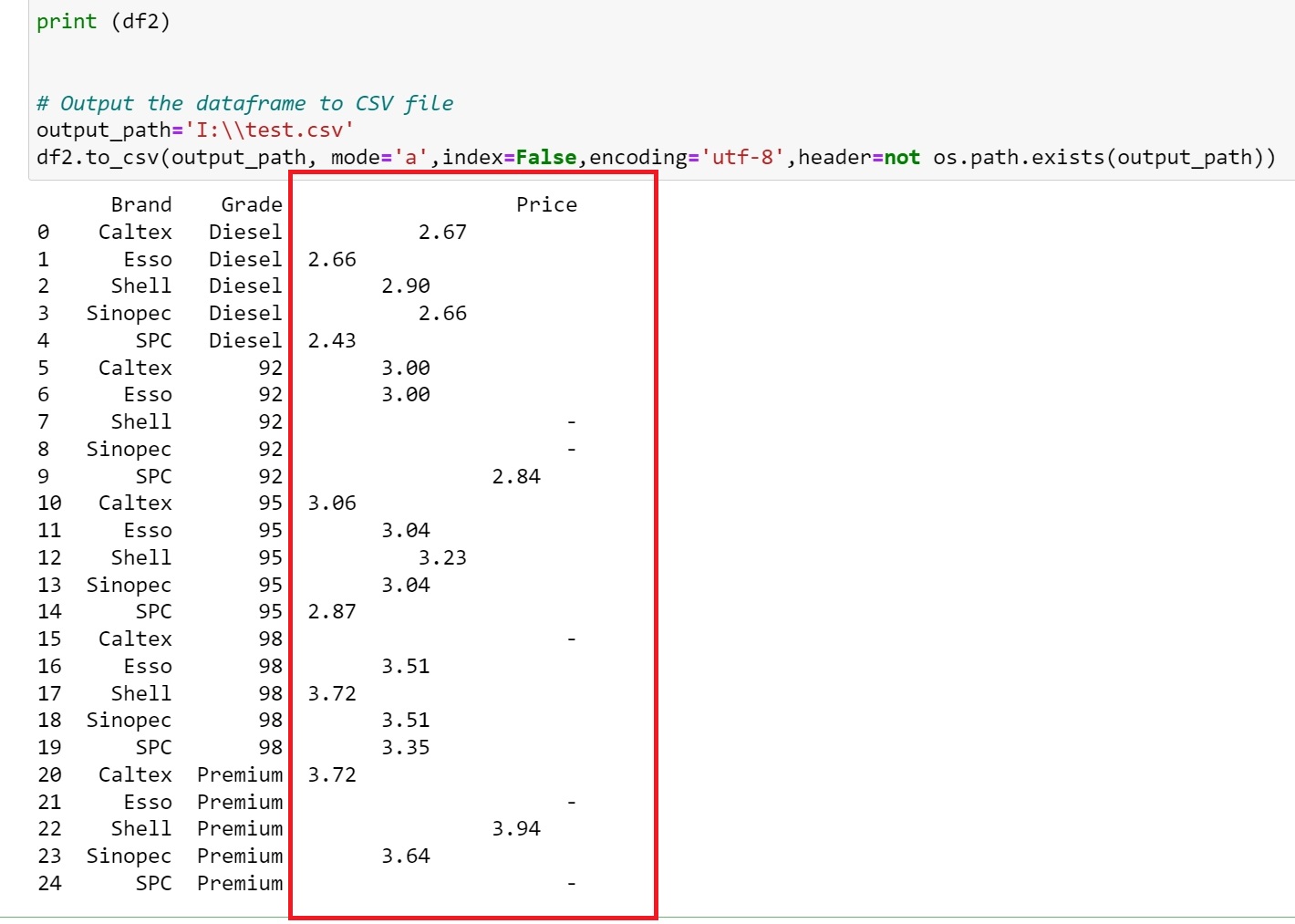
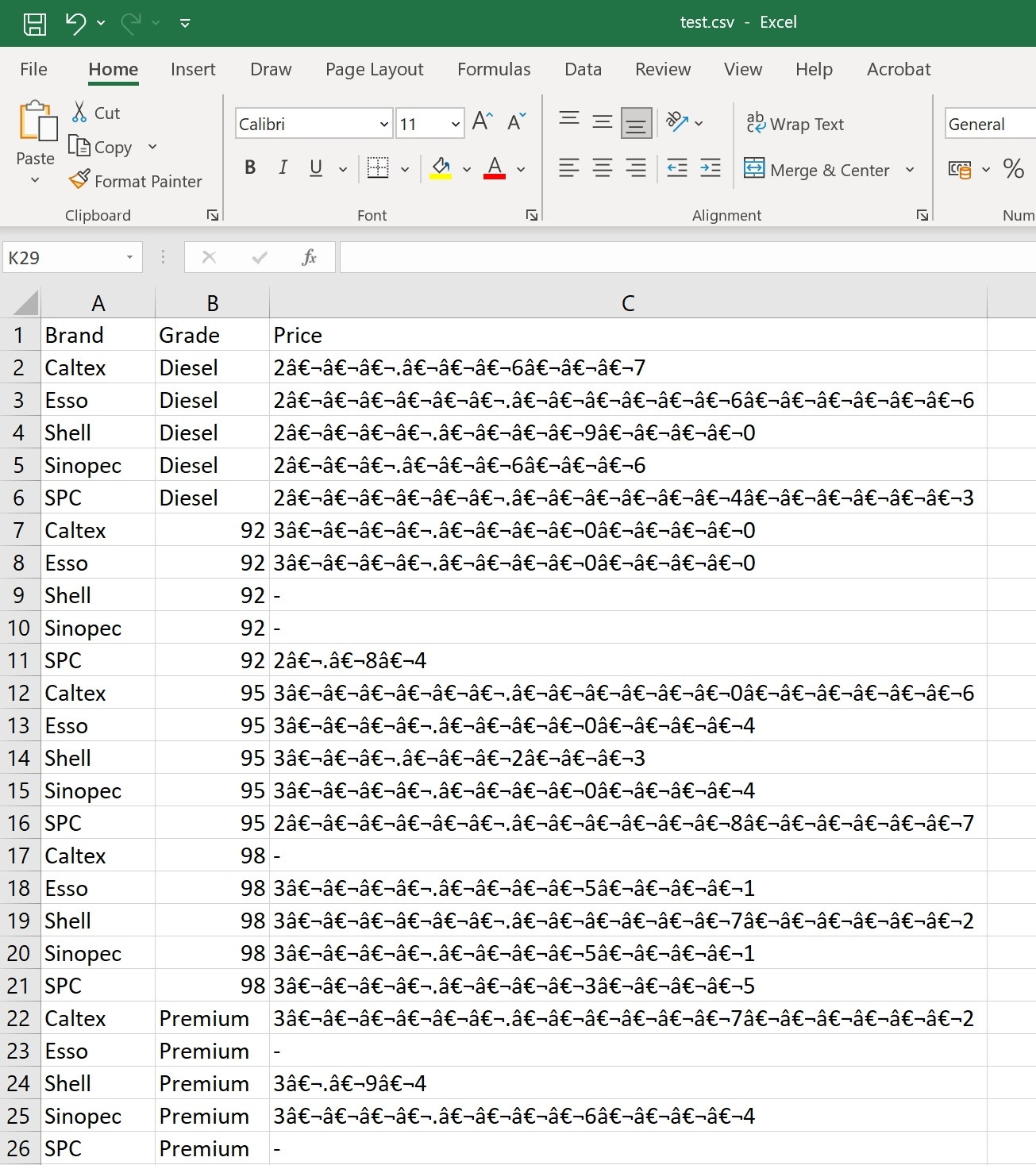
Gibberish in the output CSV:
Attached my code below so you are able to replicate the problem:
import time
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import pandas as pd
import os
# Using Selenium to Load Page and Parse with BeautifulSoup
url = 'https://fuelkaki.sg/home'
options = Options()
options.binary_location = "C:\Program Files (x86)\Google\Chrome\Application\chrome.exe"
options.add_argument('--disable-gpu')
driver = webdriver.Chrome(options=options)
driver.get(url)
time.sleep(3)
page = driver.page_source
driver.quit()
soup = BeautifulSoup(page, 'html.parser')
# Using Pandas to read the table on the page and reorganize the data
df = pd.read_html(page)
df[0].columns=['Brand','Diesel','92','95','98','Premium']
df1 = df[0]
del df1['Brand']
df1.insert(0,"Brand",["Caltex", "Esso","Shell", "Sinopec","SPC"],True)
df2=pd.melt(df[0],id_vars=['Brand'],value_vars=['Diesel','92','95','98','Premium'],var_name='Grade',value_name='Price')
# Using Pandas to clean the data in the 'Price" column
df2['Price']=df2['Price'].apply(lambda x: x.replace("Diesel", ""))
df2['Price']=df2['Price'].apply(lambda x: x.replace("Regular", ""))
df2['Price']=df2['Price'].apply(lambda x: x.replace("Extra", ""))
df2['Price']=df2['Price'].apply(lambda x: x.replace("(Synergy Supreme )", ""))
df2['Price']=df2['Price'].apply(lambda x: x.replace("(Platinum 98)", ""))
df2['Price']=df2['Price'].apply(lambda x: x.replace("(Shell V-Power)", ""))
df2['Price']=df2['Price'].apply(lambda x: x.replace("(SINO X Power)", ""))
df2['Price']=df2['Price'].apply(lambda x: x.replace("S$ ", ""))
df2['Price']=df2['Price'].apply(lambda x: x.replace("N.A.", "-"))
print (df2)
# Output the dataframe to CSV file
output_path='I:\\test.csv'
df2.to_csv(output_path, mode='a',index=False,encoding='utf-8',header=not os.path.exists(output_path))
Appreciate any advise on how to correct the spacing, remove empty spaces and fix the gibberish.
CodePudding user response:
Add this line, after all your existing apply/replace lines. After this, it prints fine. Looks like you have unicode characters, which can be encoded to ascii and ignore errors:
df2['Price']=df2['Price'].apply(lambda x: x.encode("ascii", "ignore").decode())
dataframe output
Brand Grade Price
0 Caltex Diesel 2.67
1 Esso Diesel 2.66
2 Shell Diesel 2.90
3 Sinopec Diesel 2.66
4 SPC Diesel 2.43
5 Caltex 92 3.00
6 Esso 92 3.00
Csv Output