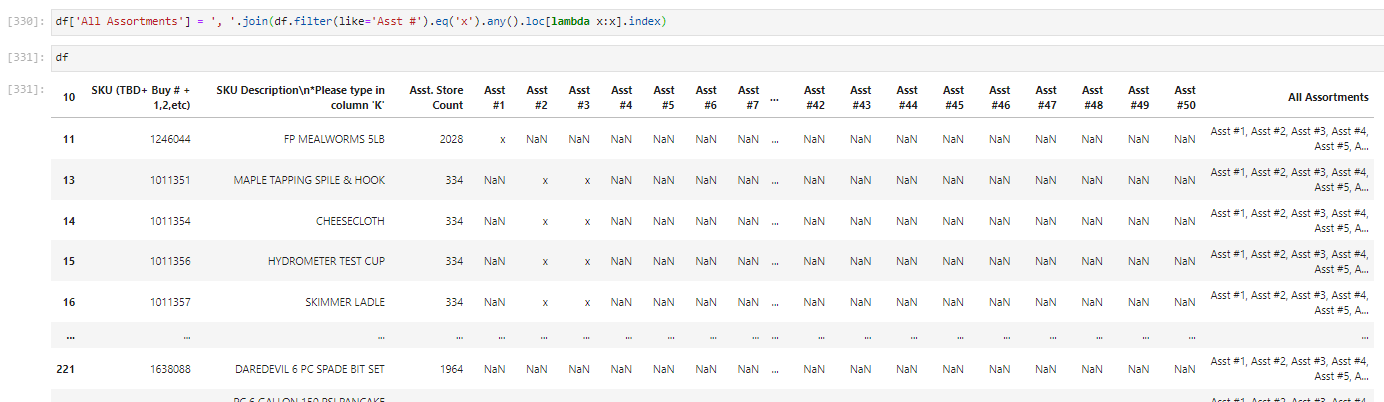
I'm trying to create a new column that contains all of the assortments (Asst 1 - 50) that a SKU may belong to. A SKU belongs to an assortment if it is indicated by an "x" in the corresponding column.
The script will need to be able to iterate over the rows in the SKU column and check for that 'x' in any of the ASST columns. If it finds one, copy the name of that assortment column into the newly created "all assortments" column.
After one Liner:
I have been attempting this using the df.apply method but I cannot seem to get it right.

def assortment_crunch(row):
if row == 'x':
df['Asst #1'].apply(assortment_crunch):
my attempt doesn't really account for the need to iterate over all of the "asst" columns and how to assign that column to the newly created one.
CodePudding user response:
I'm not sure if this is the most efficient way, but you can try this.
Instead of applying to the column, apply to the whole DF to get access to the row. Then you can iterate through each column and build up the value for the final column:
def make_all_assortments_cell(row):
assortments_in_row = []
for i in range(1, 51):
column_name = f'Asst #{i}'
if (row[column_name] == 'x').any():
assortments_in_row.append(row[column_name])
return ", ".join(assortments_in_row)
df["All Assortments"] = df.apply(make_all_assortments_cell)
I think this will work though I haven't tested it.
CodePudding user response:
Here's a super fast ("vectorized") one-liner:
asst_cols = df.filter(like='Asst #')
df['All Assortment'] = [', '.join(asst_cols.columns[mask]) for mask in asst_cols.eq('x').to_numpy()]
Explanation:
df.filter(like='Asst #')- returns all the columns that containAsst #in their name.eq('x')- exactly the same as== 'x', it's just easier for chaining functions like this because of the parentheses mess that would occur otherwiseto_numpy()- converts the mask dataframe in to a list of masks