I am currently making use of sjoin to filter points within an entire list of polygons from a json file. The issue is, if there are overlapping polygons, I want it to show the point and which polygons it is in. The points are all shapely geometries.
For example:
Point A: Polygon 1, Polygon 2
Right now it is doing:
Point A: Polygon 1
Point A: Polygon 2
I would like it to also show ONLY the points in overlapping regions, ignoring anything that is only in one if that is possible.
Sample code of what I have now:
filter = gpd.sjoin(pointdataframe, polygons, op='within')
Both pointdataframe and polygons are geodataframes. Polygons contains all the polygons, whether they are overlapping ones or individual ones.
I tried to use the groupby() function however that returned an entire list of all the points and did not format the polygons contained in each point the way I wanted above.
CodePudding user response:
- have used two sample polygons that overlap
- generate points that are linearly spaced across total bounds of this geometry
sjoin()as you have done to find points association with polygon- now
groupby()the point index. This now allows getting a list of polygons associated with a point
sample output
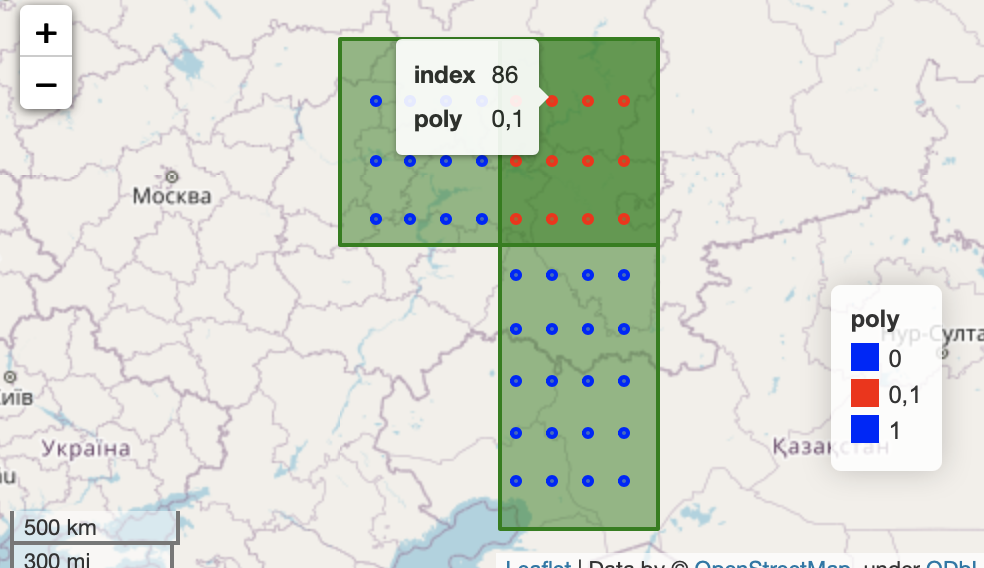
| index | geometry | poly |
|---|---|---|
| 55 | POINT (52.77777777777778 53.22222222222222) | 0 |
| 56 | POINT (54.333333333333336 53.22222222222222) | 0 |
| 57 | POINT (55.888888888888886 53.22222222222222) | 0 |
| 58 | POINT (57.44444444444444 53.22222222222222) | 0 |
| 61 | POINT (46.55555555555556 54.666666666666664) | 1 |
| 62 | POINT (48.111111111111114 54.666666666666664) | 1 |
| 63 | POINT (49.666666666666664 54.666666666666664) | 1 |
| 64 | POINT (51.22222222222222 54.666666666666664) | 1 |
| 65 | POINT (52.77777777777778 54.666666666666664) | 0,1 |
| 66 | POINT (54.333333333333336 54.666666666666664) | 0,1 |
visualised
full code
import pandas as pd
import numpy as np
import geopandas as gpd
import io
import shapely
gdf_poly = gpd.GeoDataFrame(
geometry=pd.read_csv(
io.StringIO(
"""POLYGON ((59 46, 59 59, 52 59, 52 46, 59 46))
POLYGON ((59 54, 59 59, 45 59, 45 54, 59 54))"""
),
header=None,
sep="\t",
)[0].apply(shapely.wkt.loads),
crs="epsg:4386",
)
# generate some points
gdf_point = gpd.GeoDataFrame(
geometry=[
shapely.geometry.Point(lat, lon)
for lon in np.linspace(*gdf_poly.total_bounds[[1, 3]], 10)
for lat in np.linspace(*gdf_poly.total_bounds[[0, 2]], 10)
],
crs="epsg:4386",
)
# group by points index to get common ones and associated polygon(s)
gdf_points_poly = gpd.sjoin(gdf_point, gdf_poly, op="within").reset_index().groupby("index").agg(
geometry=("geometry", "first"), poly=("index_right", lambda i: ",".join(i.astype(str).tolist()))
).set_crs("epsg:4386")
# visualise ...
m = gdf_poly.explore(height=300, width=500, color="green")
gdf_points_poly.explore(m=m, column="poly", cmap=["blue","red","blue"])