I have some files as below:
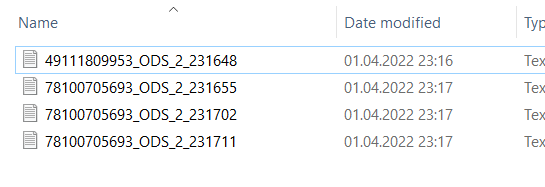
As a result, I want to have:
49111809953_1.txt
78100705693_1.txt
78100705693_2.txt
78100705693_3.txt
but now I have:
49111809953_1.txt
78100705693_**2**.txt
78100705693_3.txt
78100705693_4.txt
Anyone have any idea where I should add something to start counting over if the filename is different?
import os
import re
folderPath = r'C:/Users/a/Desktop/file'
fileSequence = 1
if os.path.exists(folderPath):
files = []
for name in os.listdir(folderPath):
if os.path.isfile(os.path.join(folderPath, name)):
files.append(os.path.join(folderPath, name))
print(files)
for ii in files:
os.rename(ii, folderPath '/' str(os.path.basename(ii).split("ODS")[0]) str(fileSequence) '.txt')
fileSequence = 1
CodePudding user response:
You need to reset your variable fileSequence each time the first part of the file name changes.
This is what I would do, based on your code:
import os
import re
folderPath = r'C:/Users/a/Desktop/file'
if os.path.exists(folderPath):
files = []
for name in os.listdir(folderPath):
if os.path.isfile(os.path.join(folderPath, name)):
files.append(os.path.join(folderPath, name))
prefix = None
for this_file in files:
current = os.path.basename(this_file).split("ODS")[0]
if prefix is None or current != prefix:
prefix = current
fileSequence = 1
os.rename(this_file, folderPath '/' prefix str(fileSequence) '.txt')
fileSequence = 1
CodePudding user response:
Suppose the following unordered list:
# After os.listdir()
files = ['C:/Users/a/Desktop/file/78100705693_ODS_2_231711.txt',
'C:/Users/a/Desktop/file/49111809953_ODS_2_231648.txt',
'C:/Users/a/Desktop/file/78100705693_ODS_2_231655.txt',
'C:/Users/a/Desktop/file/78100705693_ODS_2_231702.txt']
You can use groupby from itertools and pathlib:
from itertools import groupby
import pathlib
for name, grp in groupby(sorted(files)):
for seq, file in enumerate(grp, 1):
file = pathlib.Path(file)
new_name = f"{file.stem.split('_', maxsplit=1)[0]}_{seq}"
file.rename(file.with_stem(new_name))