So i have a large text file that looks like this :
""" Yay you made it, User1 ! — 25/03/2022 --------------- User2 joined the party. — 22/03/2022 --------------- Yay you made it, User3 ! — 29/03/2022 --------------- User4 joined the party. — 28/03/2022"""
How do i get all the names of the users, knowing they are all after or before those specific phrases with python ?
I tried :
import re
text =""" ....""" #text is here
before_j = re.findall(r'\bjust showed up\S*', text)
print(before_j)
CodePudding user response:
Use
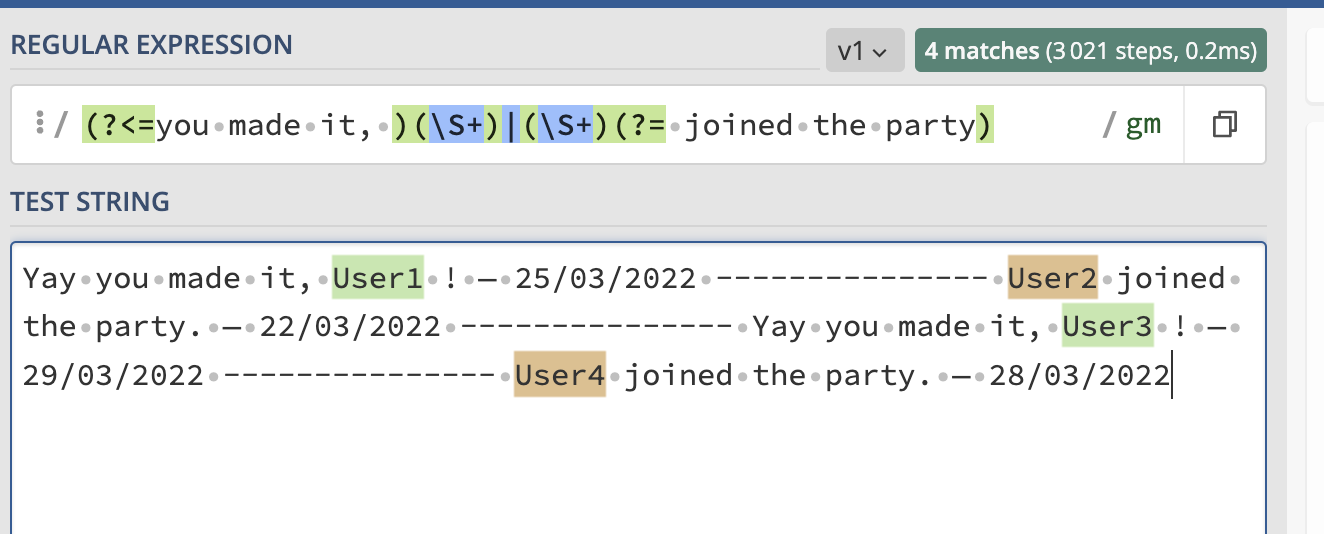
(?<=Yay you made it, )\S |\S (?= joined the party)
See 
However, I would assume that the username might be more complex, and so let's just pretend that a username is one or more non-space characters (notice, this is often not valid -- what if there is a period or exclamation point at the end -- User1!? -- in which case \w would be a better specifier). In which case, we want to match a username preceded by the words "You made it, " or succeeded by the words "joined the party". In which case we have:
import re s = "Yay you made it, User1 ! — 25/03/2022 --------------- User2 joined the party. — 22/03/2022 --------------- Yay you made it, User3 ! — 29/03/2022 --------------- User4 joined the party. — 28/03/2022" [item[0] or item[1] for item in re.findall(r'(?<=you made it, )(\S )|(\S )(?= joined the party)', s)] # ['User1', 'User2', 'User3', 'User4']CodePudding user response:
Possible solution is the following:
PROS: "User" name may have any characters except space.
import re string = """ Yay you made it, User1 ! — 25/03/2022 --------------- User2 joined the party. — 22/03/2022 --------------- Yay you made it, User3 ! — 29/03/2022 --------------- User4 joined the party. — 28/03/2022""" found = re.findall(r',\s(\S )\s!|-\s(\S )\sj', string, re.I) print(list(filter(None, [item for t in found for item in t])))Prints
['User1', 'User2', 'User3', 'User4']Thanks to @cards, @David542 for valuable comments about regex pattern.
CodePudding user response:
I settle two matching rules for the names:
it, (name_pattern) !"it," then name followed by " !"-{3,} (name_pattern)\sat least 3- characters followed by the name and an empty character where name is any sequence of alphabetic character terminating with one or more digits,([a-zA-Z] \d )
The pattern-matching is done simultaneously and needs to remove the "empty" match in the loop.
import re text = """ Yay you made it, User1 ! — 25/03/2022 --------------- User2 joined the party. — 22/03/2022 --------------- Yay you made it, User3 ! — 29/03/2022 --------------- User4 joined the party. — 28/03/2022""" # list of rules rules = (r'it, ([a-zA-Z\d] ) !', r'-{3,} ([a-zA-Z] \d )\s') # regex = '|'.join(rules) matches = [g1 if g2 == '' else g2 for g1, g2 in re.findall(regex, text)] print(matches)Output
['User1', 'User2', 'User3', 'User4']EDIT To avoid filtering the empty strings of the matched text one can use symbolic grouping (just groups with ids):
# symbolic grouping rules = (r'it, (?=<g1>[a-zA-Z\d] ) !', r'-{3,} (?=<g2>[a-zA-Z] \d )\s') regex = '|'.join(rules) matches = [g.lastgroup for g in re.finditer(regex, text)]