I have two tables in Big Query as shown: table_1 has id, properties in json format, collection columns repectively.
table_2 has collection, property_key, property_name columns
I want to replace the json keys in properties column from table_1 with property_name from table_2
condition: where tabe_1.collection = table_2.collection and also property_key in table_2 contains the actual json_key's
Table_1:
| id | properties | collection |
|---|---|---|
| workflow:623a776f04f1527a7bc2b3ed | {"counterpartyName_string":{"type":"string","value":"XYZ"},"signerc_string":{"type":"string","value":"xyz_a"},"signer3_email":{"type":"email","value":"[email protected]"},"custome54_string":{"type":"string","value":"No (default answer)"},"paperSource_string":{"type":"string","value":"Our paper"},"acceptanceType_string":{"type":"string","value":"eSignature"},"agreementDate":{"type":"date","value":"2018-04-02"},"workflowId":{"type":"string","value":"123"},"workflowCreatedDate":{"type":"date","value":"2018-03-23"},"workflowUpdatedDate":{"type":"date","value":"2022-04-02T15:16:24.688Z"},"workflowCreator":{"type":"string","value":"6008"},"workflowOwner":{"type":"string","value":"6008"},"workflowConfigurationVersionNumber":{"type":"number","value":12.0}} | 57b4c959e899aa130069e4e0 |
| 52523e7b-0a19-4551-be43-5c1d124beea0 | {"amendment":{"type":"boolean","value":false},"10vs25term":{"type":"string","value":"10 Term"},"counterpartyAddress":{"type":"string","value":"USA"},"agreementDate":{"type":"date","value":"2018-11-05"},"contractType":{"type":"string","value":"ABC"},"contactForNotice":{"type":"string","value":"UMC"},"statementOfWork":{"type":"boolean","value":false},"mastercardEntity":{"type":"string","value":"Master"},"folder":{"type":"string","value":"NDA"},"importBatch":{"type":"string","value":"Sale"},"counterpartyName":{"type":"string","value":"Gra"},"documentID":{"type":"string","value":"115"},"region":{"type":"string","value":"United States"},"effectiveDate":{"type":"date","value":"2018-11-05"}} | 5db09e5d9c32aaa121bf4ca1 |
Table_2:
| collection | property_key | property_name |
|---|---|---|
| 57b4c959e899aa130069e4e0 | counterpartyName_string | Counterparty Name |
| 57b4c959e899aa130069e4e0 | signerc_string | Counterparty Signer Name |
| 57b4c959e899aa130069e4e0 | signer3_email | Counterparty Signer Email |
| 57b4c959e899aa130069e4e0 | custome54_string | Equipment |
| 5db09e5d9c32aaa121bf4ca1 | amendment | Amendment |
| 5db09e5d9c32aaa121bf4ca1 | 10vs25term | 10 vs 25 Term |
| 5db09e5d9c32aaa121bf4ca1 | counterpartyAddress | Counterparty Address |
| 5db09e5d9c32aaa121bf4ca1 | agreementDate | Agreement Date |
I wanted the result table be like a new column with changed properties field from table_1 as shown
Result_table:
| id | properties | collection | renamed_properties |
|---|---|---|---|
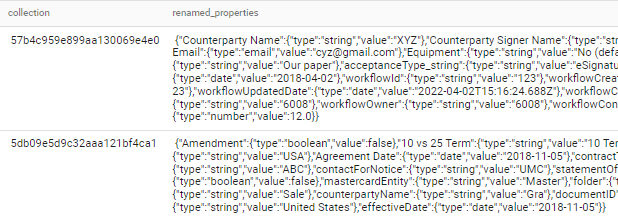
| workflow:623a776f04f1527a7bc2b3ed | {"counterpartyName_string":{"type":"string","value":"XYZ"},"signerc_string":{"type":"string","value":"xyz_a"},"signer3_email":{"type":"email","value":"[email protected]"},"custome54_string":{"type":"string","value":"No (default answer)"},"paperSource_string":{"type":"string","value":"Our paper"},"acceptanceType_string":{"type":"string","value":"eSignature"},"agreementDate":{"type":"date","value":"2018-04-02"},"workflowId":{"type":"string","value":"123"},"workflowCreatedDate":{"type":"date","value":"2018-03-23"},"workflowUpdatedDate":{"type":"date","value":"2022-04-02T15:16:24.688Z"},"workflowCreator":{"type":"string","value":"6008"},"workflowOwner":{"type":"string","value":"6008"},"workflowConfigurationVersionNumber":{"type":"number","value":12.0}} | 57b4c959e899aa130069e4e0 | {"Counterparty Name":{"type":"string","value":"XYZ"},"Counterparty Signer Name":{"type":"string","value":"xyz_a"},"Counterparty Signer Email":{"type":"email","value":"[email protected]"},"Equipment":{"type":"string","value":"No (default answer)"},"Paper Source":{"type":"string","value":"Our paper"},"Acceptance Type":{"type":"string","value":"eSignature"},"Agreement Date":{"type":"date","value":"2018-04-02"},"Workflow Id":{"type":"string","value":"123"},"Workflow Created Date":{"type":"date","value":"2018-03-23"},"Workflow Updated Date":{"type":"date","value":"2022-04-02T15:16:24.688Z"},"Workflow Creator":{"type":"string","value":"6008"},"Workflow Owner":{"type":"string","value":"6008"},"Workflow Configuration Version Number":{"type":"number","value":12.0}} |
| 52523e7b-0a19-4551-be43-5c1d124beea0 | {"amendment":{"type":"boolean","value":false},"10vs25term":{"type":"string","value":"10 Term"},"counterpartyAddress":{"type":"string","value":"USA"},"agreementDate":{"type":"date","value":"2018-11-05"},"contractType":{"type":"string","value":"ABC"},"contactForNotice":{"type":"string","value":"UMC"},"statementOfWork":{"type":"boolean","value":false},"mastercardEntity":{"type":"string","value":"Master"},"folder":{"type":"string","value":"NDA"},"importBatch":{"type":"string","value":"Sale"},"counterpartyName":{"type":"string","value":"Gra"},"documentID":{"type":"string","value":"115"},"region":{"type":"string","value":"United States"},"effectiveDate":{"type":"date","value":"2018-11-05"}} | 5db09e5d9c32aaa121bf4ca1 | {"Amendment":{"type":"boolean","value":false},"10 vs 25 Term":{"type":"string","value":"10 Term"},"Counterparty Address":{"type":"string","value":"USA"},"Agreement Date":{"type":"date","value":"2018-11-05"},"Contract Type":{"type":"string","value":"ABC"},"Contact For Notice":{"type":"string","value":"UMC"},"Statement Of Work":{"type":"boolean","value":false},"Mastercard Entity":{"type":"string","value":"Master"},"Folder":{"type":"string","value":"NDA"},"Import Batch":{"type":"string","value":"Sale"},"Counterparty Name":{"type":"string","value":"Gra"},"Document ID":{"type":"string","value":"115"},"Region":{"type":"string","value":"United States"},"Effective Date":{"type":"date","value":"2018-11-05"}} |
Can someone guide me the correct way to solve this in BigQuery using sql or sqludf's
CodePudding user response:
Consider below approach
select id, collection,
'{' || string_agg(renamed_property, ',' order by offset) || '}' renamed_properties
from (
select id, collection, property, offset,
array_agg(replace(property, property_key, property_name) order by regexp_contains(property, property_key) desc limit 1)[offset(0)] renamed_property
from table_1 t1,
unnest(regexp_extract_all(properties, r'"[^"] ":{"type":"[^"] ","value":[^}] }')) as property with offset
left join table_2 t2
using (collection)
group by id, collection, property, offset
)
group by id, collection
if applied to sample data in y our question - output is