I am running the code below to visualize online social media sentiment per month for Feb through May, 2012. However, only data for Feb and March are displayed, although I have data for April and May as well.
Code for visualization:
valence_12<-valences_by_post %>%
filter(year == 2012)%>%
group_by(month) %>%
summarize(mean_valence= mean(valence), n=n())
ggplot(valence_12, aes(x =month, y = mean_valence))
geom_point()
geom_line()
scale_x_continuous(breaks=seq(1,5,1))
geom_smooth(formula = y ~ x, method = "loess")
Output:
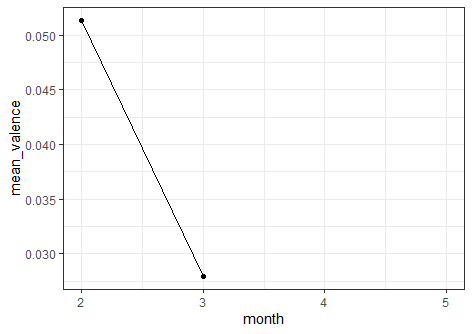
I am not sure why the mean for April-May is shown as NaN.
print(valence_12)
A tibble: 4 x 3
month mean_valence n
<dbl> <dbl> <int>
1 2 0.0514 35
2 3 0.0279 175
3 4 NaN 131
4 5 NaN 85
I am confused because when I ran the same code but visualizing sentiment by day for April, the graph displayed all as expected:
# Sentiment by day: April, 2012
valence_12<-valences_by_post %>%
filter(month == 4)%>%
group_by(day) %>%
summarize(mean_valence= mean(valence), n=n())
ggplot(valence_12, aes(x =day, y = mean_valence))
geom_point()
geom_line()
scale_x_continuous(breaks=seq(1,31,1))
geom_smooth()
Output
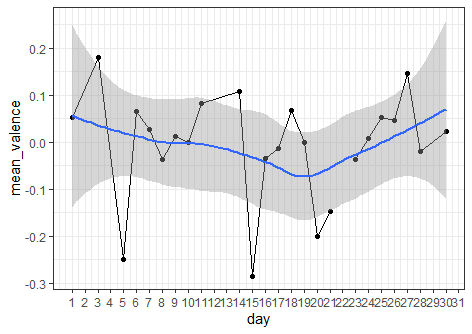
How can I overcome the "NaN" error with the April and May data?
dput(valence_12)
structure(list(month = c(2, 3, 4, 5), mean_valence = c(0.0513884517137431,
0.0279234111587779, NaN, NaN), n = c(35L, 175L, 131L, 85L)), class = c("tbl_df",
"tbl", "data.frame"), row.names = c(NA, -4L))
CodePudding user response:
You have some missing values around April 23rd - hard to see exactly with your plot. You can interpolate those values, or if you are interested in summarizing by month just do na.rm = TRUE before creating your plot:
valence_12<-valences_by_post %>%
filter(year == 2012)%>%
group_by(month) %>%
summarize(mean_valence= mean(valence, na.rm=TRUE), n=n())