I have a problem with python pandas. I have serveral different dataframes which I want to split up into an SQLite Database. My first Dataframe to_country:
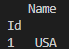
to_country = df[['country']]
to_country = to_country.rename(columns={'country': 'Name'})
to_country = to_country.drop_duplicates()
#Add Index to Country Dataframe
to_country.insert(0, 'Id', range(1, 1 len(to_country)))
to_country=to_country.reindex(columns=['Id','Name'])
to_country = to_country.set_index('Id')
to_country.to_sql('Country', con=con, if_exists='append', index=True)```
This part works fine.
Now i have another Dataframe to_state which looks like that:
to_state = df[['state','country']]
to_state = to_state.rename(columns={'state': 'Name'})
to_state = to_state.drop_duplicates()
to_state.insert(0, 'Id', range(1, 1 len(to_state)))
to_state=to_state.reindex(columns=['Id','Name','country'])
to_state = to_state.set_index('Id')
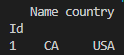
Now I want to replace the Country USA with the Id from the previous Dataframe, i want it to look like that:
Note the CountryId should be the attribute Id from the dataframe to_country Id___Name___CountryId
1_____CA_________1
I tried following Statement but which only resulted in:
to_state = pd.merge(to_state, to_country, left_on='country', right_on="Name")

I really do not know how should i solve this. what is even more irritating, I don't know why the Colums Id from both Dataframes disappear.
CodePudding user response:
As I don't have your example dataframe, test this
import pandas as pd
to_country = pd.DataFrame({"id": [20,30],
"country": ['USA','CHINA']})
to_state = pd.DataFrame({"id": [90,80],
"state": ['CA','AB'],
"country": ['USA','CHINA']})
print(f'__________ORIGINALS DATAFRAMES__________ \n##STATE##\n{to_state}\n\n###COUNTRY###\n{to_country}')
def func(line):
t = 0
for x in range(0, len(to_country['country'])):
t = to_country.loc[to_state['country'] == line['country']]
t = t.values.tolist()
return t[0][0]
print(f'\n_________FINAL DATAFRAME__________\n')
to_state['ID_NEW_country'] = to_state.apply(func, axis = 1)
print(f' \n{to_state}')
CodePudding user response:
I solved it like that in the end:
#Add Countries to Database
to_country = df[['country']]
to_country = to_country.rename(columns={'country': 'Name'})
to_country = to_country.drop_duplicates()
#Add Index to Country Dataframe
to_country = to_country.reset_index()
to_country = to_country.rename(columns={"index":"ID"})
to_country['ID'] = to_country.index 1
to_country.set_index('ID').to_sql('Country', con=con, if_exists='append', index=True)
#Add States to Database
to_state = df[['state','country']]
to_state = to_state.drop_duplicates()
#Add Index to Country Dataframe
to_state = to_state.reset_index()
to_state = to_state.rename(columns={"index":"ID", 'state': 'Name'})
to_state['ID'] = to_state.index 1
to_state = to_state.merge(to_country, how='left', left_on='country', right_on='Name').drop(['country', 'Name_y'], axis= 1)
print(to_state)
to_state = to_state.rename(columns={'ID_x': 'ID', 'Name_x': 'Name', 'ID_y': 'Country_ID'})
print(to_state)
to_state.set_index('ID').to_sql('State', con=con, if_exists='append', index=True)