I am trying to count all occurences in a dataframe that has multiple elements in each cell.
I have an original dataframe made of 2 colums and each row has multiple elements:
index x1 x2
0 "foo;bar;baz" "baz;qux;quux"
1 "foo;baz" "baz;foo;quux"
2 "quux" "quux"
and I wanted to know the preferences for each row. Maybe it's easier looking at this venn diagram.
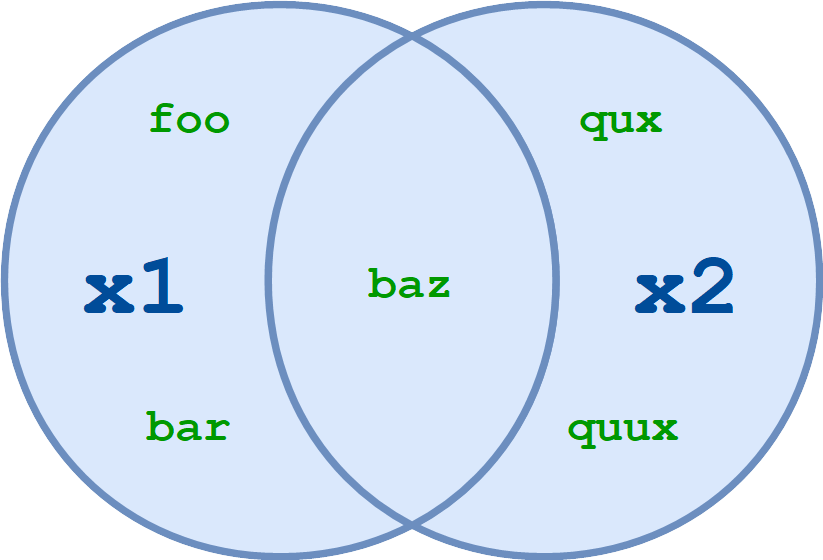
According to the image, for example index 0 will be:
- love = baz (this is the intersection of x1 and x2)
- hate = foo, bar (this is the difference between x1 and x2)
- want = qux, quux (this is the difference between x2 and x1).
I managed to make a new dataframe with all of these preferences by making this:
df2['love'] = [set(x[0].split(';')) & set(x[1].split(';')) for x in df.values]
df2['hate'] = [set(x[0].split(';')) - set(x[1].split(';')) for x in df.values]
df2['want'] = [set(x[1].split(';')) - set(x[0].split(';')) for x in df.values]
and it gives me:
love hate want
0 {baz} {foo, bar} {qux,quux}
1 {foo, baz} {} {quux}
2 {quux} {} {}
I want now to count all occurrences of every column. That is a new dataframe that'll look like this:
index love hate want
bar 0 1 0
baz 2 0 0
foo 1 1 0
qux 0 0 1
quux 1 0 2
I already have a list of all possible names that can exist in a column:
leng=[]
for l in df['x1'].apply(lambda x: x.split(';')):
leng=np.unique(np.append(leng, l))
I tried collections.Counter(itertools.chain.from_iterable(v.split(';') for v in list(df3.love))).values() but the issue now is that everytime I try to use .split() or .value_counts() to count the new dataframe I get different variations of 'set' object has no attribute 'split'
I must say that my real dataframe has over 80k rows so I'd appreciate an efficient solution.
thanks.
CodePudding user response:
You should iterate over the columns of the DataFrame:
df_counts = (
pd.DataFrame([Counter(chain.from_iterable(df3[column]))
for column in df3.columns],
index=['love', 'hate', 'want'])
.fillna(0)
.T
.sort_index()
)