The data is from Citi Bikes NYC for January 2019 to December 2019,the data can be viewed here: 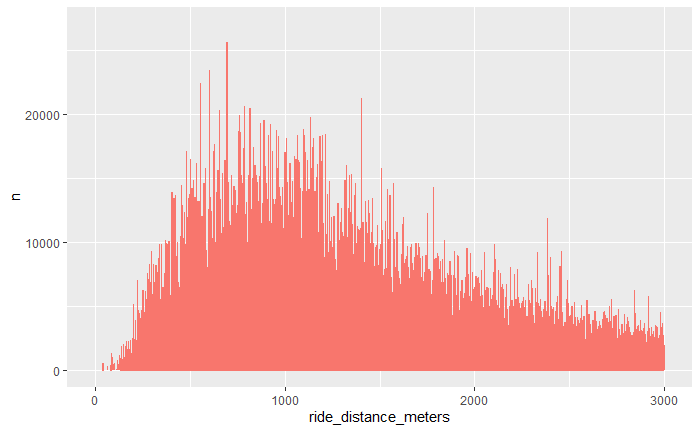
I rounded the ride_distance_meters and hoped that I would get a smoother distribution, but that did not happen:
ridedata_clean$ride_distance_mtrs_rnd <- round(ridedata_clean$ride_distance_meters,-2)
ridedata_clean %>% count(ride_distance_mtrs_rnd) |> ggplot(aes(x = ride_distance_mtrs_rnd, y= n))
geom_histogram(stat='identity', freq = FALSE, color = "#F8766D") xlim(0,3000) ylim(0,27000)
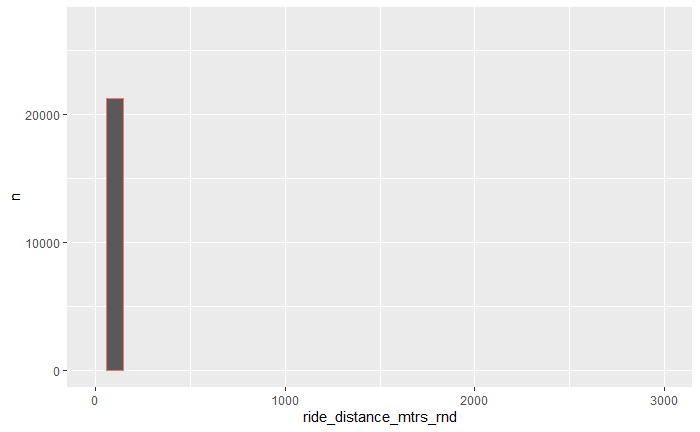
Can anyone tell me what I am doing wrong.
CodePudding user response:
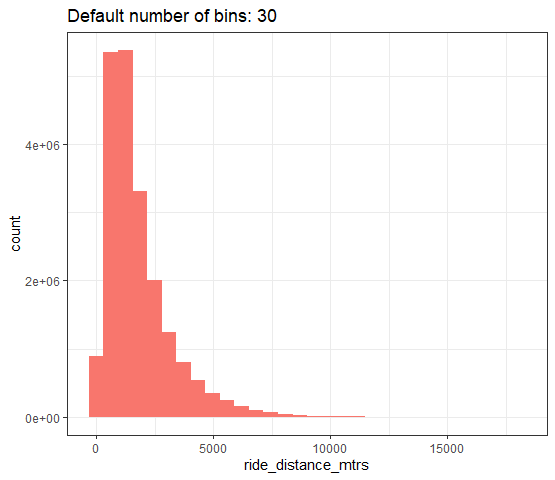
Here are the histograms. There is no need to count first nor to have an identity stat, geom_histogram will bin the data and count how many data points are in each bin automatically.
The first histogram uses the default number of bins.
library(ggplot2)
ggplot(ridedata_clean, aes(ride_distance_mtrs))
geom_histogram(fill = "#F8766D")
ggtitle(label = "Default number of bins: 30")
theme_bw()
Now vary the number of bins to see the number of bars increase, therefore making the histograms less smooth.
Base R has functions that return numbers of bins according to different criteria, see the documentation for the functions below 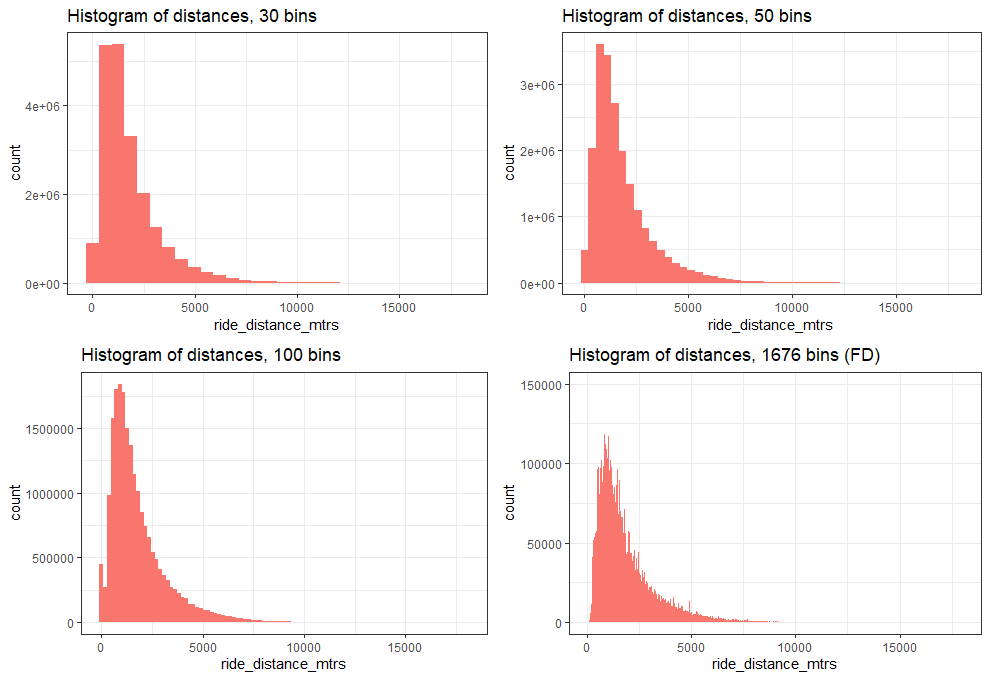
Alternatively, the bins can be set with binwidth, to give control on the bins cut points, not on the total number of bins.
# bins widths
binwidths_vec <- c(10, 50, 100, 1000)
gg_plots2 <- vector("list", length(binwidths_vec))
for(i in seq_along(bins_vec)) {
main_title <- sprintf("Histogram of distances, bin width: %d", binwidths_vec[i])
gg_plots2[[i]] <- ggplot(ridedata_clean, aes(ride_distance_mtrs))
geom_histogram(binwidth = binwidths_vec[i], fill = "#F8766D")
ggtitle(label = main_title)
theme_bw()
if(i == 1)
gg_plots2[[i]] <- gg_plots2[[i]] ylim(0, 1.25e5)
}
gridExtra::grid.arrange(grobs = gg_plots2)
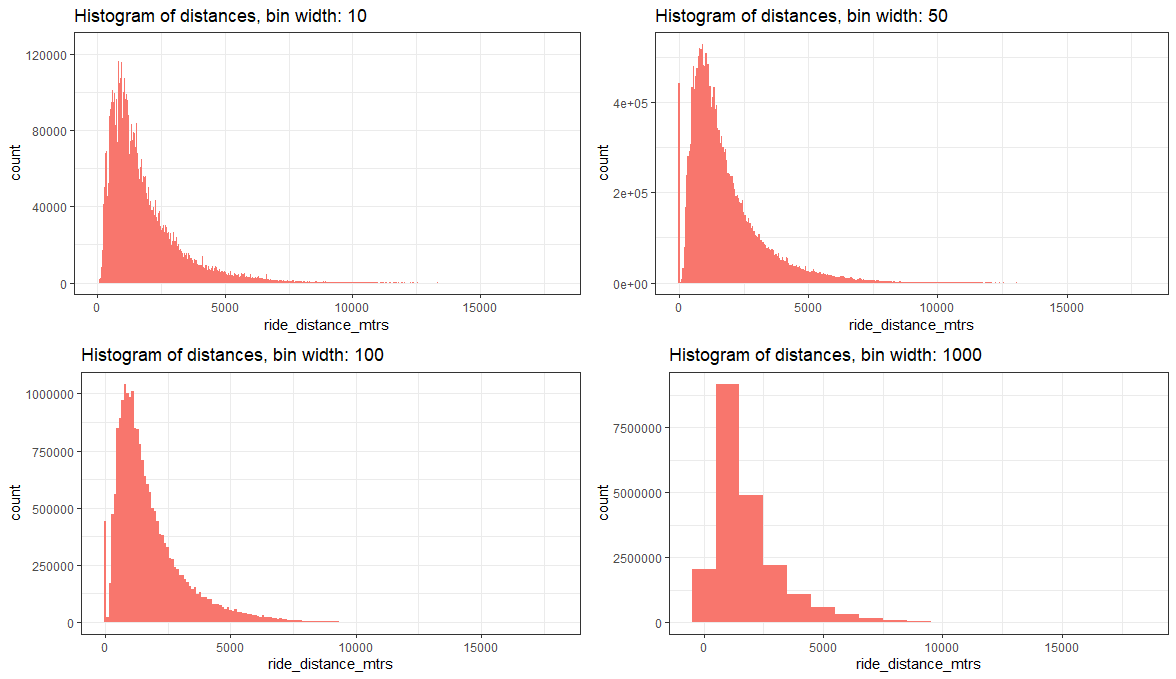
There is a visible data artifact, the first bar seems to be due to values near zero. After inspecting the data, I have found that around 2.16% of the distances are equal to zero. I have not determined the file or files those values come from.
sum(ridedata_clean$ride_distance_mtrs == 0)
# [1] 443021
100*mean(ridedata_clean$ride_distance_mtrs == 0)
# [1] 2.155642
Data
Assuming that the files were downloaded to the current directory, the following code was used to transform lon/lat coordinates to distances in meters. This takes a long time with a mid-range year 2022 PC running R 4.2.1 on Windows 11. I have not parallelized the code.
Note that the number of rows 20551697 is equal to the 5 20551692 rows in the question's posted data.
library(readr)
library(geosphere)
read_citibike_file <- function(filename, cols, verbose = TRUE) {
Y <- readr::read_csv(
file = filename,
col_types = "dddd",
col_select = all_of(cols)
)
Y <- as.matrix(Y)
if(verbose) {
mat_size <- round(utils::object.size(Y)/1024/1024, digits = 1)
cat("file:", filename, "\tdata size:", mat_size, "Mb\trows:", nrow(Y), "\n")
}
Y
}
convert_lonlat_dist <- function(data, start_cols, end_cols) {
d <- numeric(nrow(data))
for(i in seq_along(d)) {
start <- data[i, start_cols, drop = TRUE]
end <- data[i, end_cols, drop = TRUE]
tryCatch(
d[i] <- distm(start, end, fun = distHaversine),
error = function(e) print(conditionMessage(e))
)
}
d
}
zip_files <- list.files(pattern = "\\.zip$")
for(f in zip_files) unzip(f, exdir = ".")
fls <- list.files(pattern = "\\.csv$")
lon1 <- "start station longitude"
lat1 <- "start station latitude"
lon2 <- "end station longitude"
lat2 <- "end station latitude"
start_cols <- c(lon1, lat1)
end_cols <- c(lon2, lat2)
lonlat_cols <- c(start_cols, end_cols)
dist_mtrs <- sapply(fls, \(x) {
y <- read_citibike_file(x, cols = lonlat_cols)
convert_lonlat_dist(y, start_cols, end_cols)
})
dist_mtrs <- unlist(dist_mtrs)
length(dist_mtrs)
# [1] 20551697
ridedata_clean <- data.frame(ride_distance_mtrs = dist_mtrs)
nrow(ridedata_clean)
# [1] 20551697