I have a dataframe like the following:
id = c(1,2,3,4,5)
value = c(100, 200, 300, 400, 500)
tech = c('A','B','C','D','E')
tech2 = c(NA, NA,'A','B', NA)
data = data.frame(id, value, tech, tech2)
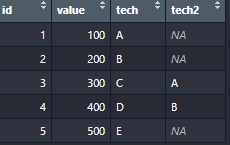
I want to convert data to the following:
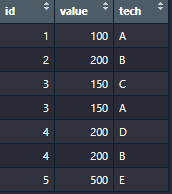
Where tech is only one column, and any id with no NA in tech 2 is duplicated and has its value split by 2 for each tech e.g. id number 3 has two techs, and a value of 300, so each tech gets 150.
I have looked at pivot_wider and pivot_longer but the examples either have numerical values within the tech column, or only one tech column.
Any suggestions?
CodePudding user response:
A possible solution:
library(tidyverse)
data %>%
mutate(
value = if_else(rowSums(is.na(across(tech:tech2))) == 0, value/2, value),
tech = paste(tech, tech2), tech2 = NULL) %>%
separate_rows(tech) %>%
filter(tech != "NA")
#> # A tibble: 7 × 3
#> id value tech
#> <dbl> <dbl> <chr>
#> 1 1 100 A
#> 2 2 200 B
#> 3 3 150 C
#> 4 3 150 A
#> 5 4 200 D
#> 6 4 200 B
#> 7 5 500 E
CodePudding user response:
A base R option using reshape ave
transform(
na.omit(
reshape(
data,
direction = "long",
idvar = c("id", "value"),
varying = -c(1:2),
v.names = "tech"
)
)[-3],
value = value / ave(value, id, FUN = length)
)
gives
id value tech
1.100.1 1 100 A
2.200.1 2 200 B
3.300.1 3 150 C
4.400.1 4 200 D
5.500.1 5 500 E
3.300.2 3 150 A
4.400.2 4 200 B