df <- data.frame(items=sample(LETTERS,replace= T),quantity=sample(1:100,26,replace=FALSE),price=sample(100:1000,26,replace=FALSE))
I want to group_by sum quantity is about 500(ballpark) ,
When count close about 500 put the same group,like below
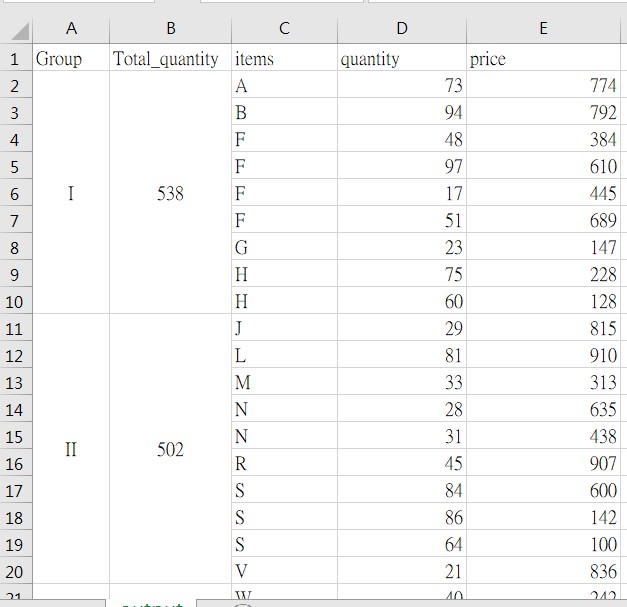
Any help would be appreciated.
CodePudding user response:
Base R
set.seed(123)
df <- data.frame(items=sample(LETTERS,replace= T),quantity=sample(1:100,26,replace=FALSE),price=sample(100:1000,26,replace=FALSE))
df$group=cumsum(c(1,ifelse(diff(cumsum(df$quantity)%P0)<0,1,0)))
df$total=ave(df$quantity,df$group,FUN=cumsum)
items quantity price group total
1 O 36 393 1 36
2 S 78 376 1 114
3 N 81 562 1 195
4 C 43 140 1 238
5 J 76 530 1 314
6 R 15 189 1 329
7 V 32 415 1 361
8 K 7 322 1 368
9 E 9 627 1 377
10 T 41 215 1 418
11 N 74 705 1 492
12 V 23 873 2 23
13 Y 27 846 2 50
14 Z 60 555 2 110
15 E 53 697 2 163
16 S 93 953 2 256
17 Y 86 138 2 342
18 Y 88 258 2 430
19 I 38 851 2 468
20 C 34 308 2 502
21 H 69 473 3 69
22 Z 72 917 3 141
23 G 96 133 3 237
24 J 63 615 3 300
25 I 13 112 3 313
26 S 25 168 3 338
CodePudding user response:
You could use Reduce(..., accumulate = TRUE) to find where the first cumulative quantity >= 500.
set.seed(123)
df <- data.frame(items=sample(LETTERS,replace= T),quantity=sample(1:100,26,replace=FALSE),price=sample(100:1000,26,replace=FALSE))
library(dplyr)
df %>%
group_by(group = lag(cumsum(Reduce(\(x, y) {
z <- x y
if(z < 500) z else 0
}, quantity, accumulate = TRUE) == 0) 1, default = 1)) %>%
mutate(total = sum(quantity)) %>%
ungroup()
# A tibble: 26 × 5
items quantity price group total
<chr> <int> <int> <dbl> <int>
1 O 36 393 1 515
2 S 78 376 1 515
3 N 81 562 1 515
4 C 43 140 1 515
5 J 76 530 1 515
6 R 15 189 1 515
7 V 32 415 1 515
8 K 7 322 1 515
9 E 9 627 1 515
10 T 41 215 1 515
11 N 74 705 1 515
12 V 23 873 1 515
13 Y 27 846 2 548
14 Z 60 555 2 548
15 E 53 697 2 548
16 S 93 953 2 548
17 Y 86 138 2 548
18 Y 88 258 2 548
19 I 38 851 2 548
20 C 34 308 2 548
21 H 69 473 2 548
22 Z 72 917 3 269
23 G 96 133 3 269
24 J 63 615 3 269
25 I 13 112 3 269
26 S 25 168 3 269
CodePudding user response:
Here is a base R solution. The groups break after the cumulative sum passes a threshold. The output of aggregate shows that all cumulative sums are above thres except for the last one.
set.seed(2022)
df <- data.frame(items=sample(LETTERS,replace= T),
quantity=sample(1:100,26,replace=FALSE),
price=sample(100:1000,26,replace=FALSE))
f <- function(x, thres) {
grp <- integer(length(x))
run <- 0
current_grp <- 0L
for(i in seq_along(x)) {
run <- run x[i]
grp[i] <- current_grp
if(run > thres) {
current_grp <- current_grp 1L
run <- 0
}
}
grp
}
thres <- 500
group <- f(df$quantity, thres)
aggregate(quantity ~ group, df, sum)
#> group quantity
#> 1 0 552
#> 2 1 513
#> 3 2 214
ave(df$quantity, group, FUN = cumsum)
#> [1] 70 133 155 224 235 327 347 409 481 484 552 29 95 129 224 263 294 377 433
#> [20] 434 453 513 50 91 182 214
Created on 2022-09-06 by the reprex package (v2.0.1)
Edit
To assign groups and total quantities to the data can be done as follows.
df$group <- f(df$quantity, thres)
df$total_quantity <- ave(df$quantity, df$group, FUN = cumsum)
head(df)
#> items quantity price group total_quantity
#> 1 D 70 731 0 70
#> 2 S 63 516 0 133
#> 3 N 22 710 0 155
#> 4 W 69 829 0 224
#> 5 K 11 887 0 235
#> 6 D 92 317 0 327
Created on 2022-09-06 by the reprex package (v2.0.1)
Edit 2
To assign only the total quantity per group use sum instead of cumsum.
df$total_quantity <- ave(df$quantity, df$group, FUN = sum)