Say I have a dataframe that looks as follows:
| Index | one | two | three |
|---|---|---|---|
| First | A | B | C |
| Second | C | A | B |
| Third | B | A | C |
My desired out is the counts of df.iloc[:,1:]: across the columns.
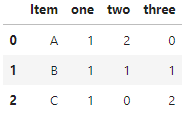
| Item | one | two | three |
|---|---|---|---|
| A | 1 | 2 | 0 |
| B | 1 | 1 | 1 |
| C | 1 | 0 | 2 |
Explanation for the second table counts in parenthesis next to each count.
| Item | one | two | three |
|---|---|---|---|
| A | 1 (Only one A in column 1) | 2 (two counts of A in column 2) | 0 (No A in column 3) |
| B | 1(Only one B in column 1) | 1 (Only one B in column 2) | 1 (1 B in column 3) |
| C | 1 (Only one C in column 1) | 0 (No Cs in column 2) | 2 (two counts of C in column 3) |
I have tried the following that did not quite work:
df3.iloc[:,1:].value_counts().to_frame('counts').reset_index()df[df.columns[1:]].value_counts()
The above two one-liners are close but not quite there.
A Macgyvered solution I can think of is to loop through the columns one by one and do .value_counts() on each of them and try to organize the counts but that gets a bit messy given the order of each .value_count is somewhat different.
How should I do this?
CodePudding user response:
Try this:
df = df.apply(pd.value_counts).fillna(0)
Hoope it helps.
CodePudding user response:
Try this :
from io import StringIO
import pandas as pd
s = """Index one two three
First A B C
Second C A B
Third B A C"""
df = pd.read_csv(StringIO(s), sep='\t').set_index('Index')
df = (df.apply(pd.value_counts).fillna(0)
.apply(pd.to_numeric,downcast='integer')
.reset_index()
.rename(columns={'index':'Item'})
)
>>> display(df)