Main topic
I am facing a problem that I am struggling a lot to solve:
Ingest files that already have been captured by Autoloader but were overwritten with new data.
Detailed problem description
I have a landing folder in a data lake where every day a new file is posted. You can check the image example below:
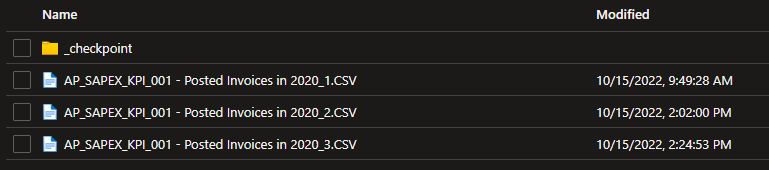
Each day an automation post a file with new data. This file is named with a suffix meaning the Year and Month of the current period of the posting.
This naming convention results in a file that is overwritten each day with the accumulated data extraction of the current month. The number of files in the folder only increases when the current month is closed and a new month starts.
To deal with that I have implemented the following PySpark code using the Autoloader feature from Databricks:
# Import functions
from pyspark.sql.functions import input_file_name, current_timestamp, col
# Define variables used in code below
checkpoint_directory = "abfss://[email protected]/RAW/Test/_checkpoint/sapex_ap_posted"
data_source = f"abfss://[email protected]/RAW/Test"
source_format = "csv"
table_name = "prod_gbs_gpdi.bronze_data.sapex_ap_posted"
# Configure Auto Loader to ingest csv data to a Delta table
query = (
spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", source_format)
.option("cloudFiles.schemaLocation", checkpoint_directory)
.option("header", "true")
.option("delimiter", ";")
.option("skipRows", 7)
.option("modifiedAfter", "2022-10-15 11:34:00.000000 UTC-3") # To ingest files that have a modification timestamp after the provided timestamp.
.option("pathGlobFilter", "AP_SAPEX_KPI_001 - Posted Invoices in *.CSV") # A potential glob pattern to provide for choosing files.
.load(data_source)
.select(
"*",
current_timestamp().alias("_JOB_UPDATED_TIME"),
input_file_name().alias("_JOB_SOURCE_FILE"),
col("_metadata.file_modification_time").alias("_MODIFICATION_TIME")
)
.writeStream
.option("checkpointLocation", checkpoint_directory)
.option("mergeSchema", "true")
.trigger(availableNow=True)
.toTable(table_name)
)
This code allows me to capture each new file and ingest it into a Raw Table.
The problem is that it works fine ONLY when a new file arrives. But if the desired file is overwritten in the landing folder the Autoloader does nothing because it assumes the file has already been ingested, even though the modification time of the file has chaged.
Failed tentative
I tried to use the option modifiedAfter in the code. But it appears to only serve as a filter to prevent files with a Timestamp to be ingested if it has the property before the threshold mentioned in the timestamp string. It dows not reingest files that have Timestamps before the modifiedAfter threshold.
.option("modifiedAfter", "2022-10-15 14:10:00.000000 UTC-3")
Question
Does someone knows how to detect a file that was already ingested but has a different modified date and how to reprocess that to load in a table?
CodePudding user response:
I have figured out a solution to this problem. In the Autoloader Options list in Databricks documentation is possible to see an option called cloudFiles.allowOverwrites. If you enable that in the streaming query then whenever a file is overwritten in the lake the query will ingest it into the target table. Please pay attention that this option will probably duplicate the data whenever a new file is overwritten. Therefore, downstream treatment will be necessary.