I have a following sql code:
with mytable(stock, datetime, price) as (
select * from values
(1, '2022-12-13 12:31:45.00'::timestamp, 10.0),
(1, '2022-12-13 12:31:45.01'::timestamp, 10.1),
(1, '2022-12-13 12:31:45.02'::timestamp, 10.2),
(1, '2022-12-13 12:31:46.00'::timestamp, 11.0),
(1, '2022-12-13 12:31:46.01'::timestamp, 11.1),
(1, '2022-12-13 12:31:46.02'::timestamp, 11.2),
(1, '2022-12-13 12:31:46.03'::timestamp, 11.3),
(1, '2022-12-13 12:31:47.03'::timestamp, 11.3),
(1, '2022-12-13 12:31:48.00'::timestamp, 11.3)
)
select t1.*
,t2.datetime as next_datetime
,t2.price as next_price
,t3.datetime as next2_datetime
,t3.price as next2_price
,t4.datetime as next3_price
,t4.price as next3_price
from mytable as t1
left join mytable as t2
on t1.stock = t2.stock and timediff(second, t1.datetime, t2.datetime) < 1
left join mytable as t3
on t1.stock = t3.stock and timediff(second, t1.datetime, t3.datetime) < 2
left join mytable as t4
on t1.stock = t4.stock and timediff(second, t1.datetime, t4.datetime) < 3
qualify row_number() over (partition by t1.stock, t1.datetime order by (t2.datetime, t3.datetime, t4.datetime) desc) = 1
ORDER BY 1,2;
With a small table, this works just fine. However, I have a table with at least 100,000 rows and doing a single left join takes about 30 minutes. Is there a better faster way to do the above operation in sql?
CodePudding user response:
There is more extensive refactoring that could be done to this query, and there is also a lot that can be done with data shaping and other techniques on these kinds of time series joins. For now, it's important to reduce the intermediate cardinality in the plan. Specifically, we want to reduce the cardinality of the join, which feeds into the window function and filter. That's currently 3,897.
Step one is to run this after running your sample query to see if the refactor produces identical results:
select hash_agg(*) from table(result_scan(last_query_id()));
This produces 1433824845005768014 when running your sample.
Now on the join, we want to restrict the number of rows that survive the join condition. Since we're looking for rows that happen in the future only, we don't have to join the ones that happen in the past:
with mytable(stock, datetime, price) as (
select * from values
(1, '2022-12-13 12:31:45.00'::timestamp, 10.0),
(1, '2022-12-13 12:31:45.01'::timestamp, 10.1),
(1, '2022-12-13 12:31:45.02'::timestamp, 10.2),
(1, '2022-12-13 12:31:46.00'::timestamp, 11.0),
(1, '2022-12-13 12:31:46.01'::timestamp, 11.1),
(1, '2022-12-13 12:31:46.02'::timestamp, 11.2),
(1, '2022-12-13 12:31:46.03'::timestamp, 11.3),
(1, '2022-12-13 12:31:47.03'::timestamp, 11.3),
(1, '2022-12-13 12:31:48.00'::timestamp, 11.3)
)
select t1.*
,t2.datetime as next_datetime
,t2.price as next_price
,t3.datetime as next2_datetime
,t3.price as next2_price
,t4.datetime as next3_price
,t4.price as next3_price
from mytable as t1
left join mytable as t2
on t1.stock = t2.stock and timediff(second, t1.datetime, t2.datetime) < 1 and t1.datetime <= t2.datetime
left join mytable as t3
on t1.stock = t3.stock and timediff(second, t1.datetime, t3.datetime) < 2 and t1.datetime <= t3.datetime
left join mytable as t4
on t1.stock = t4.stock and timediff(second, t1.datetime, t4.datetime) < 3 and t1.datetime <= t4.datetime
qualify row_number() over (partition by t1.stock, t1.datetime order by (t2.datetime, t3.datetime, t4.datetime) desc) = 1
ORDER BY 1,2;
This reduces the cardinality heading into the window function and qualify filter to 989. That's a 75% reduction of rows heading into the window function. Next, run the check again to make sure the results are identical:
select hash_agg(*) from table(result_scan(last_query_id()));
Edit: A slight change to the method of ensuring only future rows get joined reduced the intermediate cardinality from 989 to 497, an 87% reduction.
CodePudding user response:
I run your query and here is a part of the execution plan:
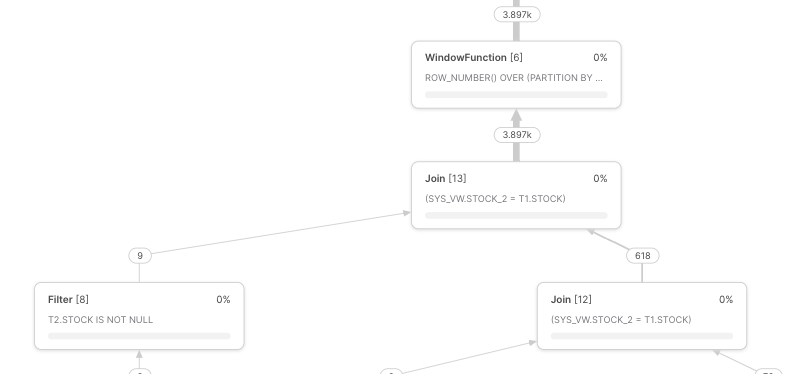
As you can see, your 9 rows became 3897 rows. If each stock has average 10 records/rows in your real table, that means even a single left join will multiply the rows by 10! If there are some stocks that have more records/rows than others, this may cause serious skewness and performance degradation.
The result of your sample query doesn't make any sense to me. Maybe your sample data has some issues because the difference between them is mostly milliseconds but your query looks for seconds. Anyway I suggest you to check LEAD function:
https://docs.snowflake.com/en/sql-reference/functions/lead.html
with mytable(stock, datetime, price) as (
select * from values
(1, '2022-12-13 12:31:45.00'::timestamp, 10.0),
(1, '2022-12-13 12:31:45.01'::timestamp, 10.1),
(1, '2022-12-13 12:31:45.02'::timestamp, 10.2),
(1, '2022-12-13 12:31:46.00'::timestamp, 11.0),
(1, '2022-12-13 12:31:46.01'::timestamp, 11.1),
(1, '2022-12-13 12:31:46.02'::timestamp, 11.2),
(1, '2022-12-13 12:31:46.03'::timestamp, 11.3),
(1, '2022-12-13 12:31:47.03'::timestamp, 11.3),
(1, '2022-12-13 12:31:48.00'::timestamp, 11.3)
)
select t1.*
,LEAD( t1.datetime) over (partition by t1.stock order by t1.datetime ) as next_datetime
,LEAD( t1.price) over (partition by t1.stock order by t1.datetime ) as next_price
,LEAD( t1.datetime, 2) over (partition by t1.stock order by t1.datetime ) as next2_datetime
,LEAD( t1.price, 2) over (partition by t1.stock order by t1.datetime ) as next2_price
,LEAD( t1.datetime, 3) over (partition by t1.stock order by t1.datetime ) as next3_datetime
,LEAD( t1.price, 3) over (partition by t1.stock order by t1.datetime ) as next3_price
from mytable as t1;
ORDER BY 1,2;
CodePudding user response:
If you quantize your data to the seconds, and pick "winner row" per second, then you can use lag/lead.
Or:
If you need each milli-second entry to be matched to the next n second rows. quantize the data to windows and double the data, then do an equi join on that, so the sliding windows are on very heavly constrained groupings
Or:
Use a user defined table function to provide aggregate/cache values, and build yourself a latch/caching scrolling window.