I am having a Nested JSON file, How can I flatten it so that I can make it compatible to upload it in SQL. This JSON file is nested and till the "in_network" key it works fine but the value "in_network" has a list of dicts so I guess my code cannot determine how to perform the task after that. I might be missing some lines of code. A help in code will be very much helpful.
{
"reporting_entity_name": "medicare",
"reporting_entity_type": "medicare",
"plan_name": "medicaid",
"plan_id_type": "hios",
"plan_id": "1111111111",
"plan_market_type": "individual",
"last_updated_on": "2020-08-27",
"version": "1.0.0",
"in_network": [
{
"negotiation_arrangement": "ffs",
"name": "Knee Replacement",
"billing_code_type": "CPT",
"billing_code_type_version": "2020",
"billing_code": "27447",
"description": "Arthroplasty, knee condyle and plateau, medial and lateral compartments",
"negotiated_rates": [
{
"provider_groups": [
{
"npi": [0],
"tin": {
"type": "ein",
"value": "11-1111111"
}
}
],
"negotiated_prices": [
{
"negotiated_type": "negotiated",
"negotiated_rate": 123.45,
"expiration_date": "2022-01-01",
"billing_class": "institutional"
}
]
}
]
}
]
}
Here is the python code I am using.
import json
import pandas as pd
with open('new_test.json', 'r') as f:
data = json.loads(f.read())
nested_data = pd.json_normalize(data, max_level=10)
After the current code the dataframe looks like
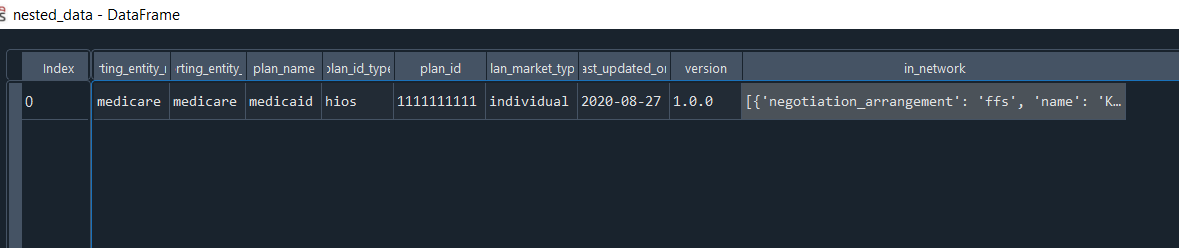
What ever is inside in_network is stored as it is but I want to store it like in_network.negotiation_arrangement a new column with value or in_network.name with its value. Something like every key has its own column.
Here is what the table
reporting_entity_name reporting_entity_type plan_name plan_id_type plan_id plan_market_type last_updated_on version in_network
0 medicare medicare medicaid hios 1111111111 individual 2020-08-27 1.0.0 [{'negotiation_arrangement': 'ffs', 'name': 'Knee Replacement', 'billing_code_type': 'CPT', 'billing_code_type_version': '2020', 'billing_code': '27447', 'description': 'Arthroplasty, knee condyle and plateau, medial and lateral compartments', 'negotiated_rates': [{'provider_groups': [{'npi': [0], 'tin': {'type': 'ein', 'value': '11-1111111'}}], 'negotiated_prices': [{'negotiated_type': 'negotiated', 'negotiated_rate': 123.45, 'expiration_date': '2022-01-01', 'billing_class': 'institutional'}]}]}]
CodePudding user response:
Using json_normalize() to parse and functools to merge:
from functools import reduce
import pandas as pd
df_main = pd.json_normalize(
data=data,
meta=["reporting_entity_name", "reporting_entity_type", "plan_name", "plan_id_type",
"plan_id", "plan_market_type", "last_updated_on", "version"],
record_path=["in_network"]
).drop(columns="negotiated_rates")
df_provider = pd.json_normalize(
data=data,
meta=["reporting_entity_name", "reporting_entity_type", "plan_name", "plan_id_type",
"plan_id", "plan_market_type", "last_updated_on", "version"],
record_path=["in_network", "negotiated_rates", "provider_groups"]
)
df_prices = pd.json_normalize(
data=data,
meta=["reporting_entity_name", "reporting_entity_type", "plan_name", "plan_id_type",
"plan_id", "plan_market_type", "last_updated_on", "version"],
record_path=["in_network", "negotiated_rates", "negotiated_prices"]
)
dfs = [df_main, df_provider, df_prices]
final_df = reduce(lambda left, right: pd.merge(
left,
right,
on=["reporting_entity_name", "reporting_entity_type", "plan_name", "plan_id_type",
"plan_id", "plan_market_type", "last_updated_on", "version"]
), dfs).explode("npi")
print(final_df)
Output:
negotiation_arrangement name billing_code_type billing_code_type_version billing_code description reporting_entity_name reporting_entity_type plan_name plan_id_type plan_id plan_market_type last_updated_on version npi tin.type tin.value negotiated_type negotiated_rate expiration_date billing_class
0 ffs Knee Replacement CPT 2020 27447 Arthroplasty, knee condyle and plateau, medial and lateral compartments medicare medicare medicaid hios 1111111111 individual 2020-08-27 1.0.0 0 ein 11-1111111 negotiated 123.45 2022-01-01 institutional