I have a parquet file with the date column filled with a data type I am having trouble with
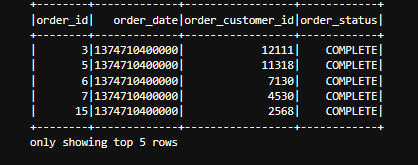
I understand that Hive and Impala tend to rebase their time stamp...However, I cannot seem to convert or find any pointers on how to solve this.
I have tried setting int96RebaseModeInRead and datetimeRebaseModeInRead mode to legacy
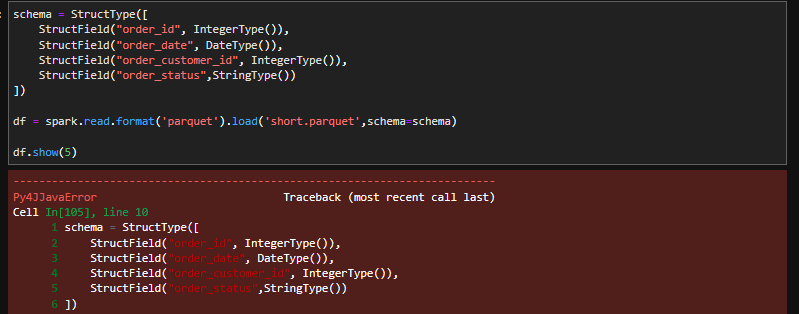
I also tried to apply a date schema onto the read operation but to no avail.
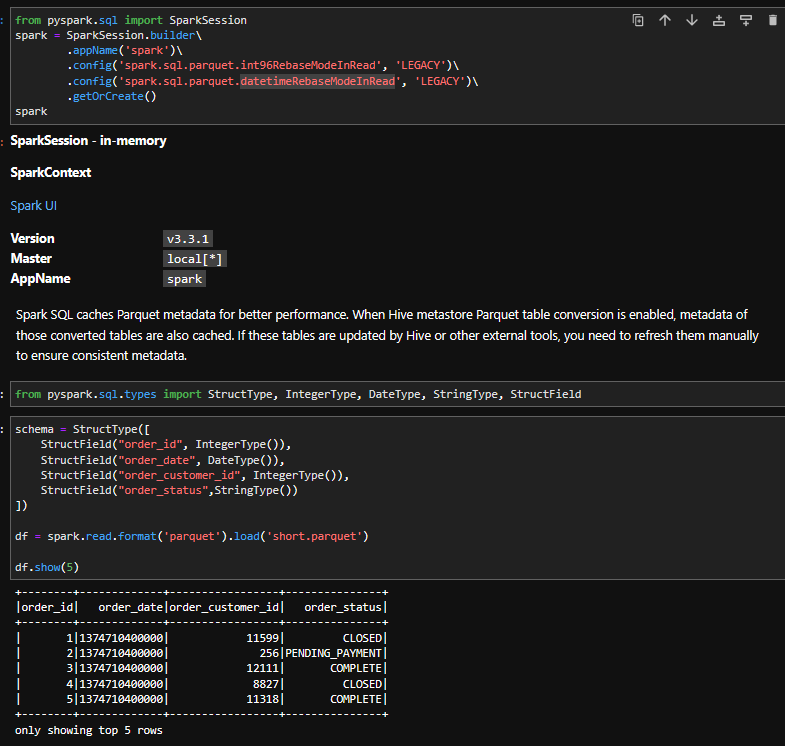
This is with schema applied

These are the documentations I've reviewed so far. Maybe there's a simple solution I am not seeing. Let's also assume that there's no way for me to ask the person who created the source file what the heck they did.
https://spark.apache.org/docs/latest/sql-data-sources-parquet.html#data-source-option
https://kontext.tech/article/1062/spark-2x-to-3x-date-timestamp-and-int96-rebase-modes
Also, this thread is the only one I was able to find that shows how the timestamp is created but not how to reverse it. Please give me some pointers. parquet int96 timestamp conversion to datetime/date via python
CodePudding user response:
As I understand you try to cast order_date column to dateType. If thats the case following code could help. You can read order_date column as stringType from source file and you should use your own timezone for from_utc_timestamp method.
from pyspark.sql.functions import from_utc_timestamp
from pyspark.sql.types import StringType
d = ['1374710400000']
df = spark.createDataFrame(d, StringType())
df.show()
df = df.withColumn('new_date',from_utc_timestamp(from_unixtime(df.value/1000,"yyyy-MM-dd hh:mm:ss"),'GMT 1')).show()
Output:
-------------
| value|
-------------
|1374710400000|
-------------
------------- -------------------
| value| new_date|
------------- -------------------
|1374710400000|2013-07-25 13:00:00|
------------- -------------------