I have the following sample df
import pandas as pd
list_of_customers =[
[202206,'patrick','lemon','fruit','citrus',10,'tesco'],
[202206,'paul','lemon','fruit','citrus',20,'tesco'],
[202206,'frank','lemon','fruit','citrus',10,'tesco'],
[202206,'jim','lemon','fruit','citrus',20,'tesco'],
[202206,'wendy','watermelon','fruit','',39,'tesco'],
[202206,'greg','watermelon','fruit','',32,'sainsburys'],
[202209,'wilson','carrot','vegetable','',34,'sainsburys'],
[202209,'maree','carrot','vegetable','',22,'aldi'],
[202209,'greg','','','','','aldi'],
[202209,'wilmer','sprite','drink','',22,'aldi'],
[202209,'jed','lime','fruit','citrus',40,'tesco'],
[202209,'michael','lime','fruit','citrus',12,'aldi'],
[202209,'andrew','','','','33','aldi'],
[202209,'ahmed','lime','fruit','fruit',33,'aldi']
]
df = pd.DataFrame(list_of_customers,columns = ['date','customer','item','item_type','fruit_type','cost','store'])
(df)
I then define variable for each category we need to aggregate
fruit_variable = df['item_type'].isin(['fruit'])
vegetable_variable = df['item_type'].isin(['vegetable'])
citrus_variable = df['fruit_type'].isin(['citrus'])
I then want to aggregate each variable and merge them into one dataframe. For each variable I want to have a separate field (variable_number) that has a number assigned to each, so we know what variable rule was used for aggregation. So for fruit_variable the field will be '01', vegetable variable will be '02' and so on. Note we can't assign a new field with each variable and include it in the grouby fields as there are rows that would not be mutually exclusive (i.e rows need to aggregate for both the fruit_variable and citrus_variable).
list_agg = df.where(fruit_variable).groupby(['date','store'])[['cost']].sum().reset_index().agg(list),
df.where(vegetable_variable).groupby(['date','store'])[['cost']].sum().reset_index().agg(list),
df.where(citrus_variable).groupby(['date','store'])[['cost']].sum().reset_index().agg(list)
print(list_agg)
type(list_agg)
df_agg = pd.DataFrame(list_Agg, columns = ['date','store','cost'])
print(df_agg)
I am having trouble converting the tuple to a dataframe.
I can convert the groupby object's to lists using .to_records().tolist() but it still leaves me the problem of how to add the new row with the variable number.
Note this is a much smaller subset of the actual problem. I am hoping to get a dataframe looking like below in this example:
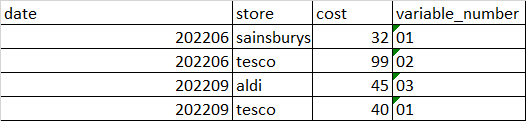
Please let me know if any further information is required.
CodePudding user response:
The exact logic is unclear, but you might want to use concat with a list comprehension of groupby.agg:
variables = {'01': df['item_type'].isin(['fruit']),
'02': df['item_type'].isin(['vegetable']),
'03': df['fruit_type'].isin(['citrus']),
}
out = (pd.concat({k: df[m].groupby(['date', 'store'], as_index=False)['cost'].sum()
for k, m in variables.items()}, names=['variable_number', None])
.reset_index('variable_number')
)
print(out)
Output:
variable_number date store cost
0 01 202206 sainsburys 32
1 01 202206 tesco 99
2 01 202209 aldi 45
3 01 202209 tesco 40
0 02 202209 aldi 22
1 02 202209 sainsburys 34
0 03 202206 tesco 60
1 03 202209 aldi 12
2 03 202209 tesco 40
CodePudding user response:
IIUC, you can use concat:
list_agg = [df.where(fruit_variable).groupby(['date','store'])[['cost']].sum().reset_index().agg(list),
df.where(vegetable_variable).groupby(['date','store'])[['cost']].sum().reset_index().agg(list),
df.where(citrus_variable).groupby(['date','store'])[['cost']].sum().reset_index().agg(list)]
out = (pd.concat(list_agg, keys=[f'{v 1:02}' for v in range(len(list_agg))])
.rename_axis(['variable_number', None])
.reset_index('variable_number').reset_index(drop=True))
Output:
>>> out
variable_number date store cost
0 01 202206.0 sainsburys 32
1 01 202206.0 tesco 99
2 01 202209.0 aldi 45
3 01 202209.0 tesco 40
4 02 202209.0 aldi 22
5 02 202209.0 sainsburys 34
6 03 202206.0 tesco 60
7 03 202209.0 aldi 12
8 03 202209.0 tesco 40