I have the following data frame (dput provided):
structure(list(Poor_health = c(2, 1, 3, 2, 2, 2, 2, 1, 2, 2,
2, 2, 2, 1, 2, 2, 2, 2, 2, 2, 2, 1, 2, 3, 1, 4, 1, 1, 3, 2, 4,
2, 3, 3, 3, 3, 4, 2, 2, 1, 3, 1, 1, 1, 1, 1, 1, 4, 2, 4, 2, 4,
2, 1, 1, 2, 1, 1, 1, 1, 2, 2, 2, 1, 2, 2, 2, 2, 2, 3, 2, 2, 2,
2, 2, 4, 2, 2, 2, 2, 2, 1, 2, 2, 2, 1, 1, 1, 2, 2, 4, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 1, 2, 3, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 2,
2, 1, 2, 2, 2, 2, 2, 2, 4, 1, 4, 4, 4, 2, 1, 2, 1, 4, 4, 1, 2,
2, 2, 2, 1, 2, 2, 2, 3, 2, 2, 2, 2, 2, 4, 1, 2, 2, 4, 4, 2, 3,
3, 2, 3, 2, 2, 2, 2, 2, 2), Family_breakdown = c(2, 3, 3, 3,
2, 3, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 1, 2, 2, 1, 2, 1, 4, 4,
3, 2, 2, 4, 3, 4, 2, 3, 3, 4, 3, 4, 3, 3, 1, 4, 1, 1, 1, 1, 1,
1, 4, 2, 3, 4, 4, 3, 1, 3, 3, 1, 1, 2, 3, 1, 2, 3, 1, 3, 2, 2,
2, 2, 3, 3, 3, 3, 2, 3, 4, 2, 2, 4, 2, 2, 3, 3, 2, 2, 4, 3, 2,
2, 2, 3, 3, 3, 1, 2, 2, 3, 2, 2, 2, 2, 2, 3, 2, 2, 2, 2, 2, 2,
2, 1, 2, 2, 2, 2, 1, 2, 2, 2, 2, 3, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 3, 2, 2, 1, 2, 2, 2, 4, 2, 4, 4, 4, 1, 4,
4, 4, 4, 4, 1, 2, 3, 4, 4, 1, 3, 2, 3, 3, 2, 2, 4, 3, 3, 4, 2,
2, 2, 3, 4, 2, 3, 3, 3, 3, 4, 3, 3, 3, 2, 3), Level_of_income = c(3,
2, 3, 2, 2, 3, 2, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 3, 3, 3, 3, 1,
2, 3, 2, 2, 3, 2, 3, 3, 3, 3, 3, 3, 3, 3, 4, 2, 3, 2, 4, 1, 1,
1, 1, 1, 1, 4, 2, 3, 1, 3, 4, 2, 1, 2, 1, 1, 2, 2, 2, 3, 2, 2,
3, 3, 3, 2, 4, 2, 2, 2, 2, 2, 2, 4, 2, 2, 3, 2, 3, 1, 3, 2, 2,
2, 1, 2, 2, 2, 2, 2, 4, 2, 2, 2, 2, 4, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 1, 2, 4, 2, 2, 2, 2, 2, 1, 3, 2, 2, 2, 2, 2, 4, 1, 4, 4,
4, 1, 2, 4, 4, 4, 1, 1, 2, 4, 2, 4, 1, 3, 2, 3, 2, 2, 2, 2, 2,
3, 2, 2, 2, 2, 2, 4, 2, 3, 3, 3, 3, 1, 3, 2, 3, 2, 3), village_subvillage = c("TenaTeke",
"TenaTeke", "TenaTeke", "TenaTeke", "TenaTeke", "TenaTeke", "TenaTeke",
"TenaTeke", "TenaTeke", "TenaTeke", "TenaTeke", "TenaTeke", "TenaTeke",
"TenaTeke", "TenaTeke", "TenaTeke", "TenaTeke", "TenaTeke", "TenaTeke",
"TenaTeke", "TenaTeke", "TenaTeke", "TenaTeke", "TenaTeke", "TenaTeke",
"TenaTeke", "TenaTeke", "TenaTeke", "TenaTeke", "TenaTeke", "TenaTeke",
"TenaTeke", "TenaTeke", "TenaTeke", "TenaTeke", "TenaTeke", "TenaTeke",
"TenaTeke", "TenaTeke", "TenaTeke", "TenaTeke", "TenaTeke", "TenaTeke",
"TenaTeke", "TenaTeke", "TenaTeke", "TenaTeke", "TenaTeke", "TenaTeke",
"TenaTeke", "TenaTeke", "TenaTeke", "Mandugo", "TenaTeke", "TenaTeke",
"TenaTeke", "TenaTeke", "TenaTeke", "Mandugo", "Mandugo", "Mandugo",
"Mandugo", "Mandugo", "Mandugo", "Mandugo", "Mandugo", "Mandugo",
"Mandugo", "Mandugo", "Mandugo", "Mandugo", "Mandugo", "Mandugo",
"Mandugo", "Mandugo", "Mandugo", "Mandugo", "Mandugo", "Mandugo",
"Mandugo", "Mandugo", "Mandugo", "Mandugo", "Mandugo", "Mandugo",
"Mandugo", "Mandugo", "Mandugo", "Mandugo", "Mandugo", "Mandugo",
"Mandugo", "Mandugo", "Mandugo", "Mandugo", "Mandugo", "Mandugo",
"Mandugo", "Mandugo", "Mandugo", "Mandugo", "Mandugo", "Mandugo",
"Mandugo", "Mandugo", "Mandugo", "Mandugo", "Mandugo", "Mandugo",
"Mandugo", "Mandugo", "Mandugo", "Mandugo", "Mandugo", "Mandugo",
"Mandugo", "Mandugo", "Mandugo", "Mandugo", "Mandugo", "Mandugo",
"Mandugo", "Mandugo", "Mandugo", "Mandugo", "Mandugo", "Mandugo",
"Mandugo", "Mandugo", "Mandugo", "Mandugo", "Mandugo", "Mandugo",
"Mandugo", "Mandugo", "Mandugo", "Mandugo", "Mandugo", "Mandugo",
"Mandugo", "Mandugo", "Mandugo", "Mandugo", "Mandugo", "TenaTeke",
"TenaTeke", "Mandugo", "TenaTeke", "TenaTeke", "TenaTeke", "TenaTeke",
"TenaTeke", "TenaTeke", "TenaTeke", "TenaTeke", "TenaTeke", "TenaTeke",
"Mandugo", "Mandugo", "Mandugo", "Mandugo", "TenaTeke", "TenaTeke",
"TenaTeke", "TenaTeke", "TenaTeke", "TenaTeke", "TenaTeke", "TenaTeke",
"TenaTeke", "TenaTeke", "TenaTeke", "TenaTeke", "TenaTeke", "TenaTeke",
"TenaTeke", "TenaTeke", "TenaTeke", "TenaTeke", "TenaTeke", "TenaTeke",
"TenaTeke", "TenaTeke", "TenaTeke", "TenaTeke", "TenaTeke", "TenaTeke"
)), row.names = c(NA, -187L), class = c("tbl_df", "tbl", "data.frame"
))
Apologies for the length (in an unfortunate time crunch to get this posted).
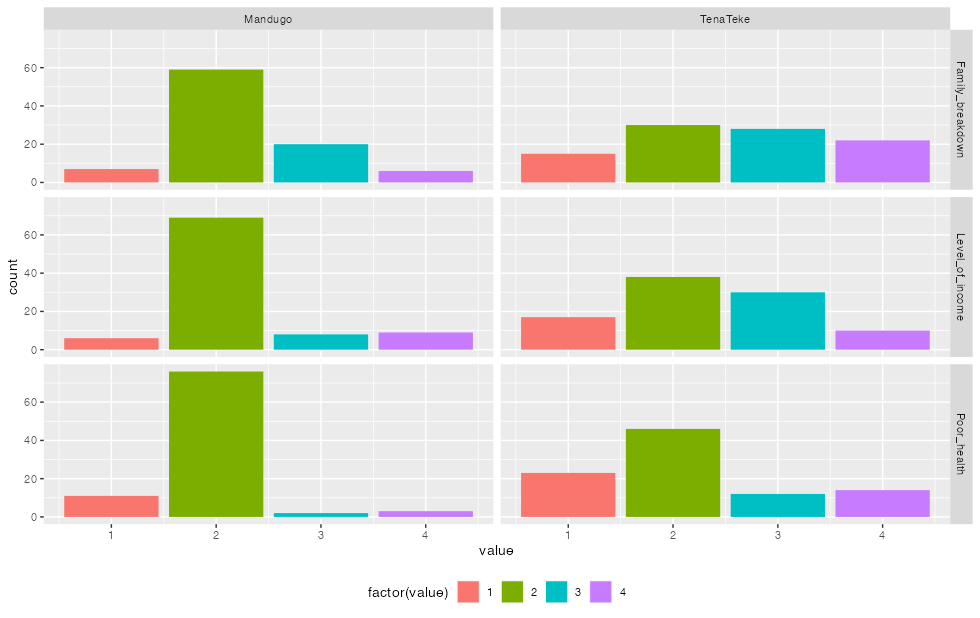
I need to create a 2x3 facet wrapped set of 6 bar graphs where the two columns of the facet grid contain the two villages, and the three rows of the facet grid contain the three variables (poor health, family breakdown and level of income).
The y axes need to show a count of the frequency of each of the value within the three variables (so obviously, the x axes will contain 5 bins for numbers 1-5).
I suspect that step one will be reshaping the data. I did something almost exactly like this yesterday with no problem, but I am a little hung up here.
CodePudding user response:
Maybe like this using tidyr::pivot_longer to reshape your data:
library(tidyr)
library(ggplot2)
dat |>
pivot_longer(-village_subvillage) |>
ggplot(aes(value, fill = factor(value)))
geom_bar()
facet_grid(name~village_subvillage)
theme(legend.position = "bottom")