I have a unit test that fails about 1 out of 30 times, I don't understand why. Here is a simplified version of it:
@Test
void size() {
int totalIndexes = 10;
Set<Integer> usedIndexes = new HashSet<>();
AtomicInteger index = new AtomicInteger();
Stream.generate(() -> index.getAndIncrement() % totalIndexes).parallel().limit(1000).forEach(i -> {
try {
Thread.sleep(1);
} catch (InterruptedException ignore) {}
usedIndexes.add(i);
});
if (usedIndexes.size() > totalIndexes) {
// Should be impossible?
System.out.println(usedIndexes.stream().map(i -> String.format("%s %d", i, i.hashCode()))
.collect(Collectors.joining(" | ")));
System.out.println("Total: " usedIndexes.size());
}
assertTrue(usedIndexes.size() <= totalIndexes);
}
The sleep is there just to make sure several threads are used, as it seems to be connected to the problem (not sure). Without it, the problem occurred after about 30K runs.
As you can see I added prints for the bad case and got some example outputs such as:
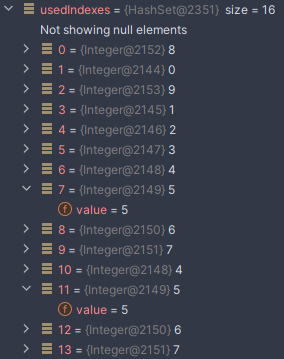
0 0 | 1 1 | 2 2 | 3 3 | 4 4 | 5 5 | 6 6 | 7 7 | 8 8 | 9 9
Total: 26
8 8 | 0 0 | 9 9 | 1 1 | 2 2 | 3 3 | 4 4 | 5 5 | 6 6 | 7 7 | 4 4 | 5 5 | 6 6 | 7 7
Total: 16
Breakpoint screenshot:
Furthermore, not trusting my years writing Java I decided to ask ChatGPT about it:
Me:
Consider this test: Can usedIndexes ever be bigger than 10 objects? How? [code above]
Chat:
The value of usedIndexes should always be less than or equal to totalIndexes because the stream is generating integers between 0 and totalIndexes - 1 (inclusive) by using the modulo operator % and the getAndIncrement() method on the AtomicInteger object index. The stream is then limited to 1000 elements, so it will not generate more than 1000 integers. Since the usedIndexes set only stores unique integers, its size should never be greater than totalIndexes.
It is possible that usedIndexes can be equal to totalIndexes if every number generated is unique and it is also possible that usedIndexes can be smaller than totalIndexes if some of the generated numbers are same. This is because, the HashSet only stores unique elements and the size of the set will be the number of unique elements.
I must be missing something simple here. Using latest IntelliJ, Java 17.
CodePudding user response:
HashSet does not support concurrent access. Use ConcurrentHashMap.newKeySet() instead.
From HashSet's docs:
Note that this implementation is not synchronized. If multiple threads access a hash set concurrently, and at least one of the threads modifies the set, it must be synchronized externally.
As you are adding elements from within a terminal operation of a parallel stream, you are breaking HashSet's contract, thus experiencing the inconsistent results you have described.