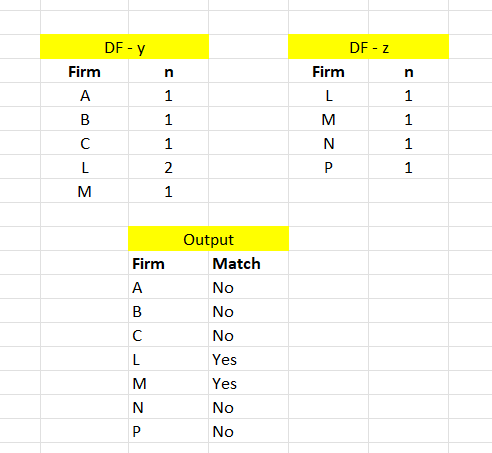
I have two data frames with a column each having different or same categorical values as coded and illustrated below.
DF1 <- data.frame(Firm1 = c("A", "B", "C", "L", "M", "L"))
DF2 <- data.frame(Firm2 = c("L", "M", "N", "P"))
library(dplyr)
y <- DF1 %>% group_by(Firm1) %>%
dplyr:: summarise(n = n())
z <- DF2 %>% group_by(Firm2) %>%
dplyr:: summarise(n = n())
I tried using %in% logic but it isn't working. Some of the other pages that I checked on columns/data frames match also couldn't help. Kindly suggest how to get this coded. Thanks.
CodePudding user response:
You can use union and intersect and %in%.
. <- union(DF1$Firm1, DF2$Firm2)
data.frame(Fimr = ., Match = c("No", "Yes")[1 . %in% intersect(DF1$Firm1, DF2$Firm2)])
# Fimr Match
#1 A No
#2 B No
#3 C No
#4 L Yes
#5 M Yes
#6 N No
#7 P No
CodePudding user response:
Similar approach to @GKi, but result is always sorted by firm.
x <- list(DF2$Firm2, DF1$Firm1)
data.frame(Firm=sort(do.call(union, x))) |>
transform(Match=c("No", "Yes")[Firm %in% do.call(intersect, x) 1L])
# Firm Match
# 1 A No
# 2 B No
# 3 C No
# 4 L Yes
# 5 M Yes
# 6 N No
# 7 P No