Is there a way where I can group my dataframe based on specific columns and include empty value as well but only when all of the values of the specific column is empty.
Example:
I have a dataframe that look like this:
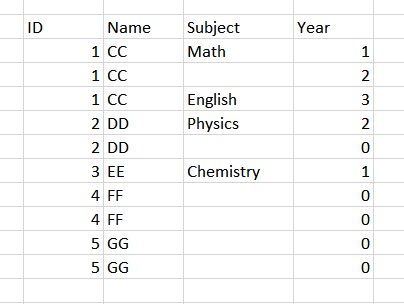
I am trying to group the dataframe based on Name and Subject.
and my expected output looks like this:
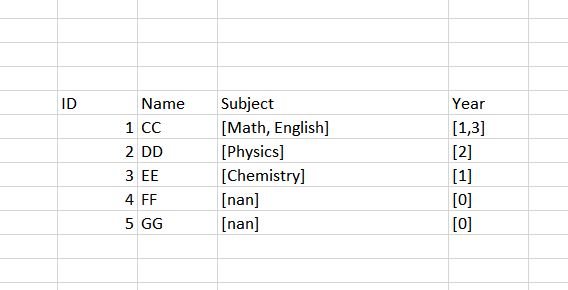
So, if a person takes more than one subject but one of them is empty, then drop the row so when aggregating the other rows it wont be included. If a person takes only one subject and it is empty then dont drop the row
[Updated]
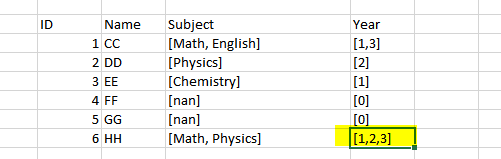
Original dataframe
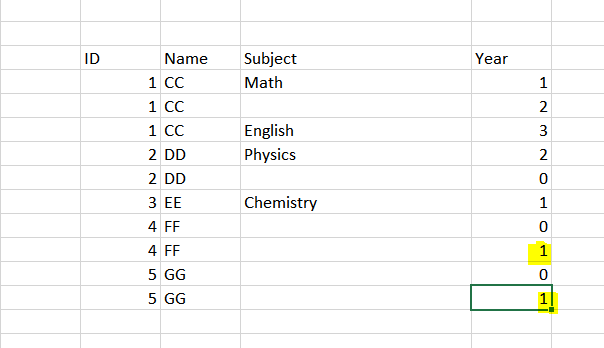
Outcome will still be the same. It will takes the first row value if all subjects of a person is empty
[Updated] Another new dataframe
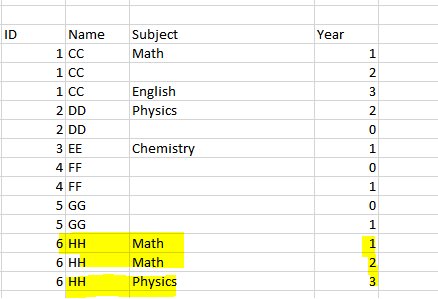
Outcome will have the same number of subjects but there will be 3 year
CodePudding user response:
Here is a proposition with GroupBy.agg :
df = df.drop_duplicates(subset=["ID", "Name", "Subject"])
m = (df.groupby(["ID", "Name"])["Subject"].transform("size").gt(1)
& df["Subject"].isnull())
out = df.loc[~m].groupby(["ID", "Name"], as_index=False).agg(list)
Output :
print(out)
ID Name Subject Year
0 1 CC [Math, English] [1, 3]
1 2 DD [Physics] [2]
2 3 EE [Chemistry] [1]
3 4 FF [nan] [0]
4 5 GG [nan] [0]