I have a pandas dataframe with many rows. In each row I have an object and the duration of the machining on a certain machine (with a start time and an end time). Each object can be processed in several machines in succession. I need to find the actual duration of all jobs. For example:
| Object | Machine | T start | T end |
|---|---|---|---|
| 1 | A | 17:26 | 17:57 |
| 1 | B | 17:26 | 18:33 |
| 1 | C | 18:56 | 19:46 |
| 2 | A | 14:00 | 15:00 |
| 2 | C | 14:30 | 15:00 |
| 3 | A | 12:00 | 12:30 |
| 3 | C | 13:00 | 13:45 |
For object 1 the actual duration is 117 minutes,for object 2 is 60 minutes and for object 3 is 75 minutes. I tried with a groupby where I calculated the sum of the durations of the processes for each object and the minimum and maximum values, i.e. the first start and the last end. Then I wrote a function that compares these values but it doesn't work in case of object 1, and it works for object 2 and 3. Here my solution:
| Object | min | max | sumT | LT_ACTUAL |
|---|---|---|---|---|
| 1 | 17:26 | 19:46 | 148 | 140 ERROR! |
| 2 | 14:00 | 15:00 | 90 | 60 OK! |
| 3 | 12:00 | 13:45 | 75 | 75 OK! |
def calc_lead_time(min_t_start, max_t_end, t_sum):
t_max_min = (max_t_end - min_t_start) / pd.Timedelta(minutes=1)
if t_max_min <= t_sum:
return t_max_min
else:
return t_sum
df['LT_ACTUAL'] = df.apply(lambda x : calc_lead_time(x['min'], x['max'], x['sumT']), axis=1)
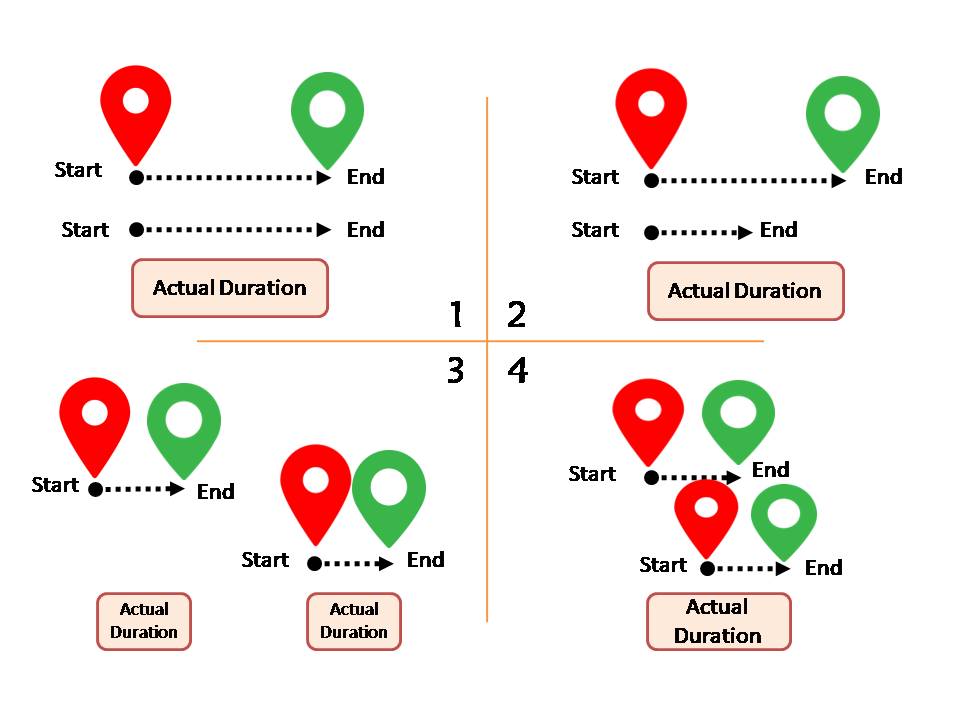
I posted an image to explane all the cases. I need to calc the actual duration between the tasks
CodePudding user response:
Assuming the data is sorted by start time, and that one task duration is not fully within another one, you can use:
start = pd.to_timedelta(df['T start'] ':00')
end = pd.to_timedelta(df['T end'] ':00')
s = start.groupby(df['Object']).shift(-1)
(end.mask(end.gt(s), s).sub(start)
.groupby(df['Object']).sum()
)
Output:
Object
1 0 days 01:57:00
2 0 days 01:00:00
3 0 days 01:15:00
dtype: timedelta64[ns]
For minutes:
start = pd.to_timedelta(df['T start'] ':00')
end = pd.to_timedelta(df['T end'] ':00')
s = start.groupby(df['Object']).shift(-1)
(end.mask(end.gt(s), s).sub(start)
.groupby(df['Object']).sum()
.dt.total_seconds().div(60)
)
Output:
Object
1 117.0
2 60.0
3 75.0
dtype: float64
handling overlapping intervals
See here for the logic of the overlapping intervals grouping.
(df.assign(
start=pd.to_timedelta(df['T start'] ':00'),
end=pd.to_timedelta(df['T end'] ':00'),
max_end=lambda d: d.groupby('Object')['end'].cummax(),
group=lambda d: d['start'].ge(d.groupby('Object')['max_end'].shift()).cumsum()
)
.groupby(['Object', 'group'])
.apply(lambda g: g['end'].max()-g['start'].min())
.groupby(level='Object').sum()
.dt.total_seconds().div(60)
)
Output:
Object
1 117.0
2 60.0
3 75.0
4 35.0
dtype: float64
Used input:
Object Machine T start T end
0 1 A 17:26 17:57
1 1 B 17:26 18:33
2 1 C 18:56 19:46
3 2 A 14:00 15:00
4 2 C 14:30 15:00
5 3 A 12:00 12:30
6 3 C 13:00 13:45
7 4 A 12:00 12:30
8 4 C 12:00 12:15
9 4 D 12:20 12:35
CodePudding user response:
def function1(dd:pd.DataFrame):
col1=dd.apply(lambda ss:pd.date_range(ss["T start"] pd.to_timedelta("1 min"),ss["T end"],freq="min"),axis=1).explode()
min=col1.min()-pd.to_timedelta("1 min")
max=col1.max()
sumT=col1.size
LT_ACTUAL=col1.drop_duplicates().size
return pd.DataFrame({"min":min.strftime('%H:%M'),"max":max.strftime('%H:%M'),"sumT":sumT,"LT_ACTUAL":LT_ACTUAL,},index=[dd.name])
df1.groupby('Object').apply(function1).droplevel(0)
out:
min max sumT LT_ACTUAL
1 17:26 19:46 148 117
2 14:00 15:00 90 60
3 12:00 13:45 75 75