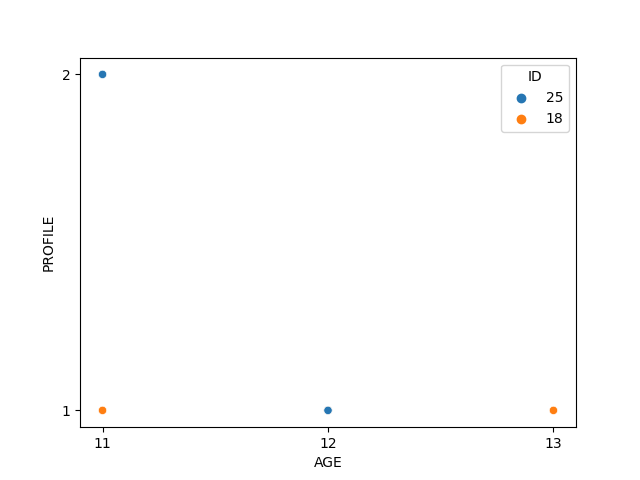
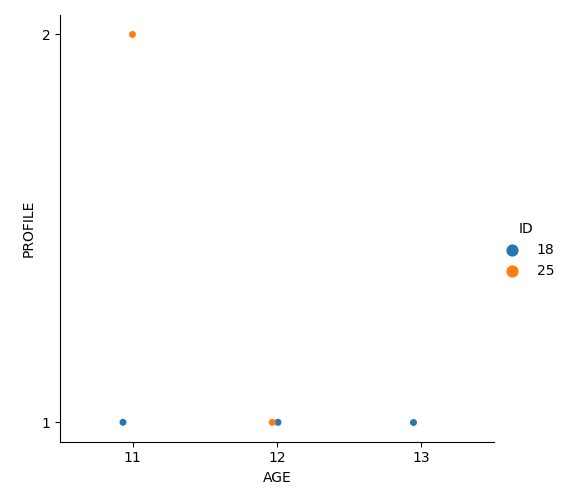
I have such a data frame
import pandas as pd
sample_df = pd.DataFrame({'ID': [25,25,25,18,18,18],
'AGE': [11,11,12,11,12,13],
'RECORD':[1,2,2,1,1,2]})
| ID | AGE | RECORD |
|---|---|---|
| 25 | 11 | 1 |
| 25 | 11 | 2 |
| 25 | 12 | 2 |
| 18 | 11 | 1 |
| 18 | 12 | 1 |
| 18 | 13 | 2 |
I would like to plot number of profiles vs age given this dataframe. My expectation is to have a plot for each age, for example age 11, there should be 3 profiles. Or for age 12, there should be 2 profiles. I tried using df.query, but I ended up confusing. Could you help me?
Expected output should look like below. Legend is not necessary for each ID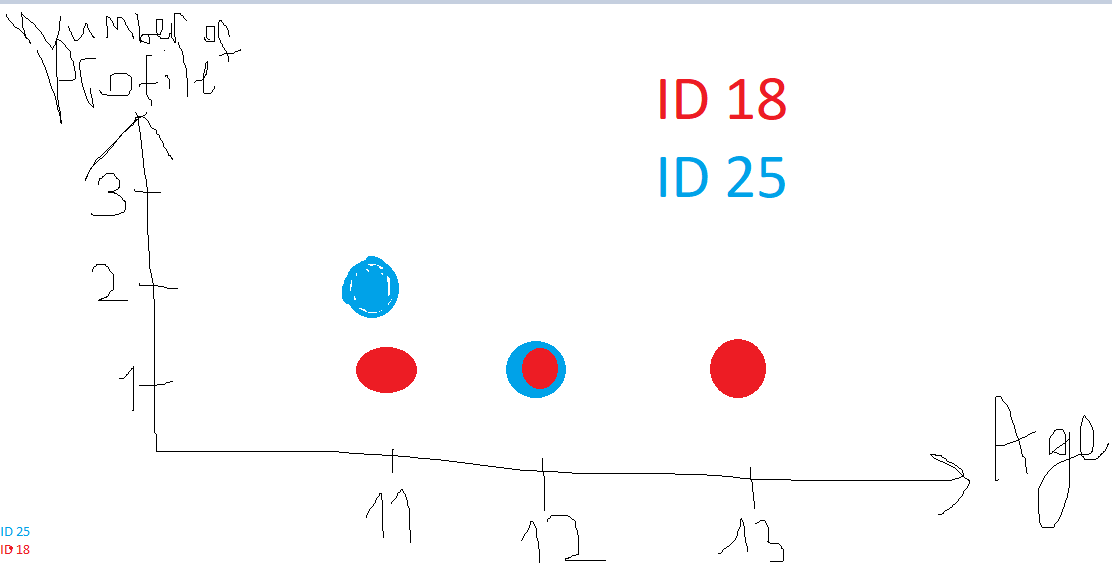
CodePudding user response:
Try:
sample_df.groupby('AGE')['ID'].count().plot(rot=0, title='Number Of Profiles', marker='o', linestyle='none')
Output:
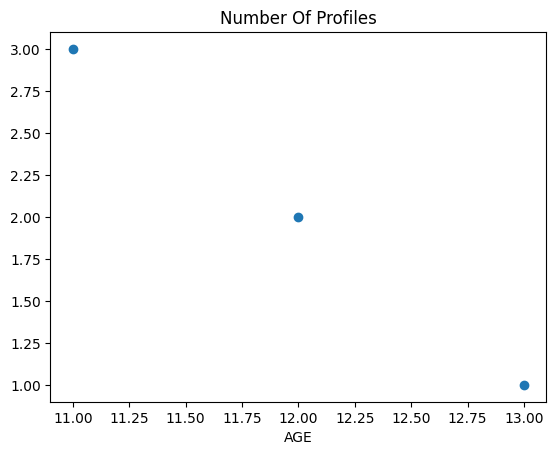
CodePudding user response:
You can specify column name whose values will be used to color the marker points according to a colormap:
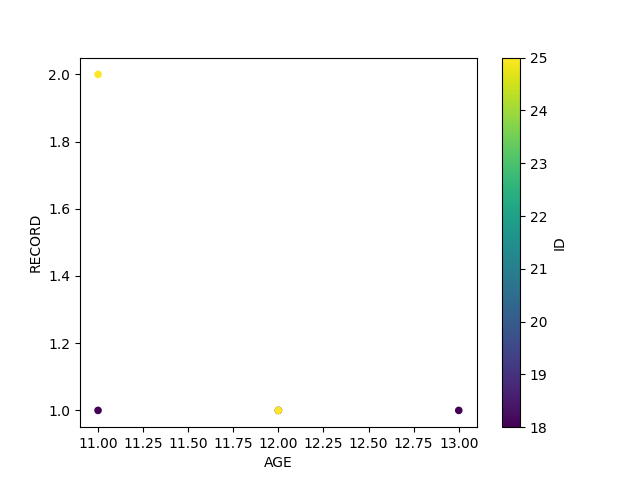
sample_df.groupby(['AGE', 'ID']).count().reset_index()\
.plot.scatter(x='AGE', y='RECORD', c='ID', colormap='viridis')
CodePudding user response:
Using seaborn but transform your dataframe first:
import seaborn as sns
import matplotlib.pyplot as plt
df1 = (sample_df.value_counts(['ID', 'AGE']).to_frame('PROFILE')
.reset_index().astype(str))
sns.scatterplot(data=df1, x='AGE', y='PROFILE', hue='ID')
# OR
sns.catplot(data=df1.sort_values('PROFILE', ascending=True), x='AGE', y='PROFILE', hue='ID')
plt.show()