I'm running into a ValueError: Columns must be same length as key when trying to do encoding for the column Type. Here are the codes, not sure which part is wrong.
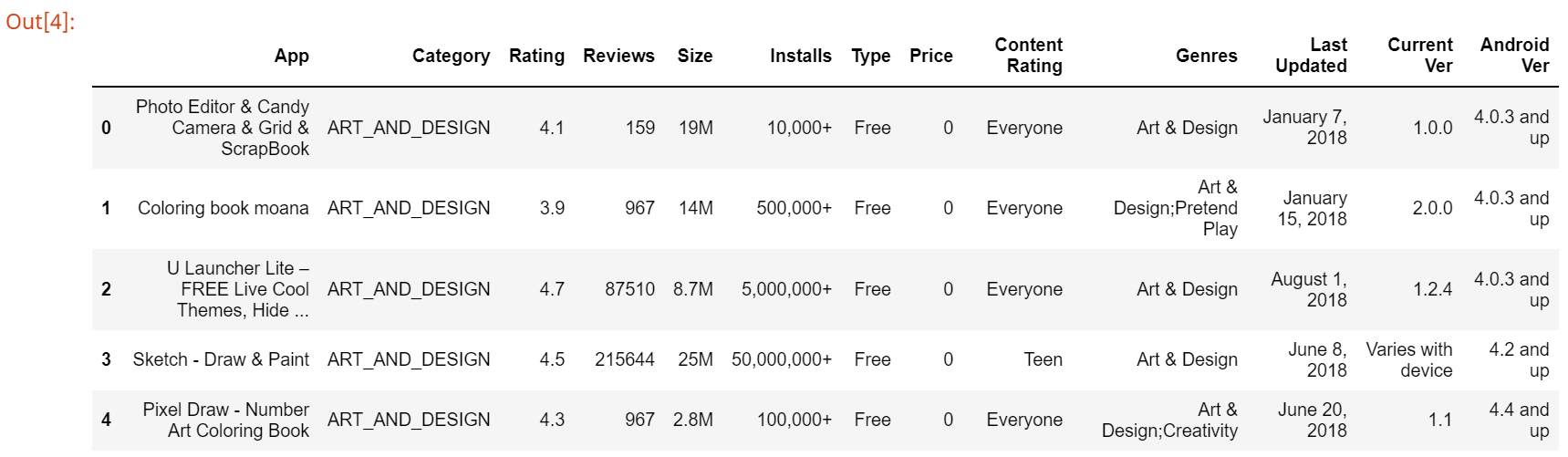
df.head()
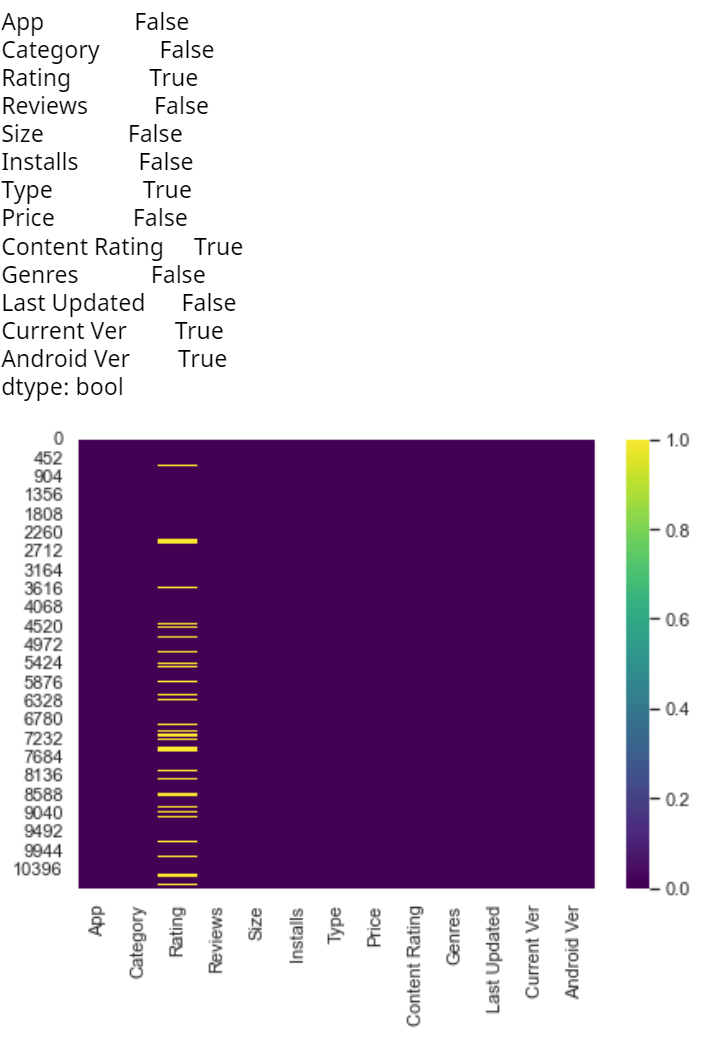
plt.figure(figsize=(7, 5))
sns.heatmap(df.isnull(), cmap='viridis')
df.isnull().any()
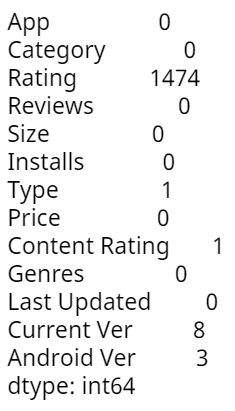
df.isnull().sum()
df['Rating'] = df['Rating'].fillna(df['Rating'].median())
replaces = [u'\u00AE', u'\u2013', u'\u00C3', u'\u00E3', u'\u00B3', '[', ']', "'"]
for i in replaces:
df['Current Ver'] = df['Current Ver'].astype(str).apply(lambda x : x.replace(i, ''))
regex = [r'[- |/:/;(_)@]', r'\s ', r'[A-Za-z] ']
for j in regex:
df['Current Ver'] = df['Current Ver'].astype(str).apply(lambda x : re.sub(j, '0', x))
df['Current Ver'] = df['Current Ver'].astype(str).apply(lambda x : x.replace('.', ',',1).replace('.', '').replace(',', '.',1)).astype(float)
df['Current Ver'] = df['Current Ver'].fillna(df['Current Ver'].median())

i = df[df['Category'] == '1.9'].index
df.loc[i]

df = df.drop(i)
df = df[pd.notnull(df['Last Updated'])]
df = df[pd.notnull(df['Content Rating'])]
le = preprocessing.LabelEncoder()
df['App'] = le.fit_transform(df['App'])
category_list = df['Category'].unique().tolist()
category_list = ['cat_' word for word in category_list]
df = pd.concat([df, pd.get_dummies(df['Category'], prefix='cat')], axis=1)
le = preprocessing.LabelEncoder()
df['Genres'] = le.fit_transform(df['Genres'])
le = preprocessing.LabelEncoder()
df['Content Rating'] = le.fit_transform(df['Content Rating'])
df['Price'] = df['Price'].apply(lambda x : x.strip('$'))
df['Installs'] = df['Installs'].apply(lambda x : x.strip(' ').replace(',', ''))
df['Type'] = pd.get_dummies(df['Type'])
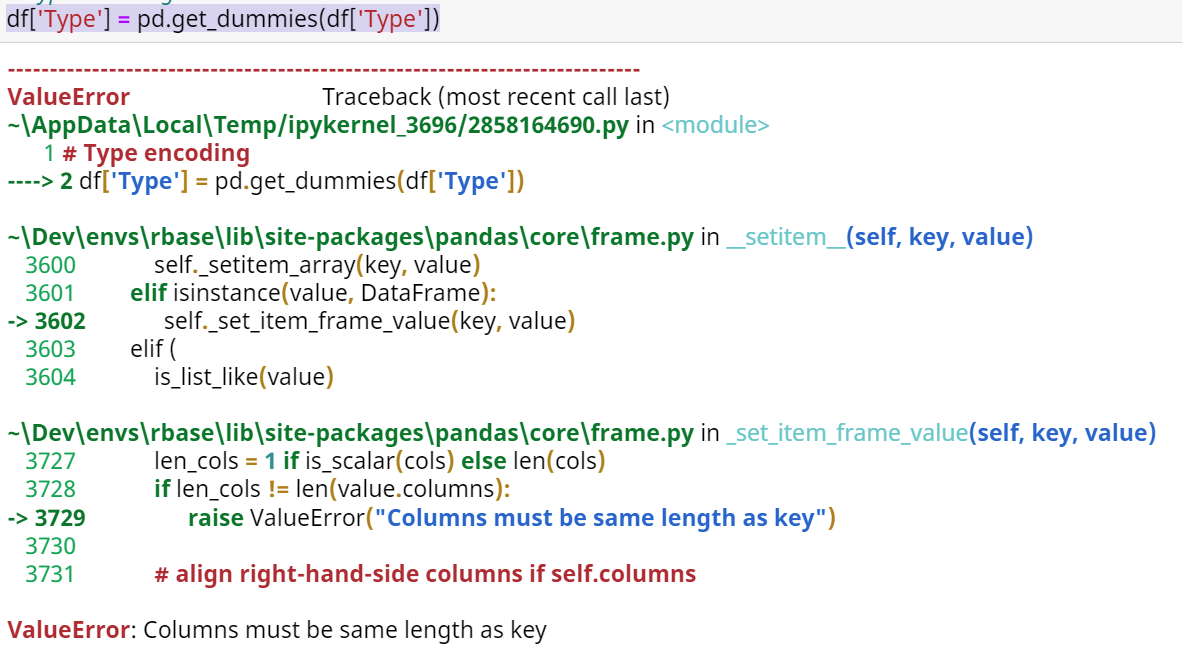
CodePudding user response:
You are trying to map a DataFrame with multiple columns to one column to the original DataFrame.
pd.get_dummies returns a DataFrame with a column for each value in the column.
If you want to add those values to the original DataFrame you can use concat.
Example:
import pandas as pd
df = pd.DataFrame(data=['type1', 'type2', 'type3'], columns=['Type'])
dummies_df = pd.get_dummies(df['Type'])
pd.concat([df, dummies_df], axis=1)