Here I am trying to get the value of every column in the table shown in the picture (for three different pages) and store them in pandas dataframe. I have collected the data and now I have a list of lists, but when I try to add them to a dictionary I get empty dictionary. can anyone help me what I'm doing wrong or suggest an alternative way to create 3 dataframes, one for each table?
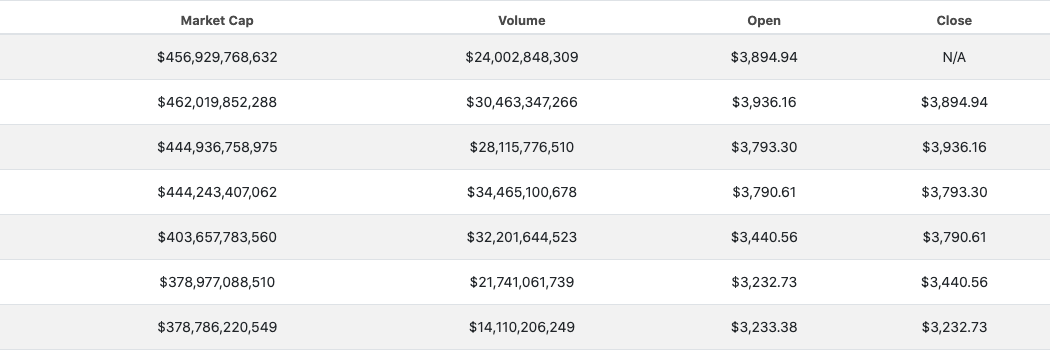
Here is my code:
import numpy as np
import pandas as pd
from datetime import datetime
import pytz
import requests
import json
from bs4 import BeautifulSoup
url_list = ['https://www.coingecko.com/en/coins/ethereum/historical_data/usd?start_date=2021-08-06&end_date=2021-09-05#panel',
'https://www.coingecko.com/en/coins/cardano/historical_data/usd?start_date=2021-08-06&end_date=2021-09-05#panel',
'https://www.coingecko.com/en/coins/chainlink/historical_data/usd?start_date=2021-08-06&end_date=2021-09-05#panel']
results = []
for url in url_list:
response = requests.get(url)
src = response.content
soup = BeautifulSoup(response.text , 'html.parser')
results.append(soup.find_all( "td",class_= "text-center"))
collected_data = dict()
for result in results:
for r in result:
datas = r.find_all("td", title=True)
for data in datas:
collected_data.setdefault(data.text)
collected_data
CodePudding user response:
What happens?
In your first for loop your are only append the result set of soup.find_all( "td",class_= "text-center") to results.
So you wont find what you are looking for with datas = r.find_all("td", title=True)
Note also, that the column headers are not placed in <td> but in <th>.
How to fix?
You could select more specific, all <tr> in <tbody> to iterate over:
for row in soup.select('tbody tr'):
While iterating select the <th> and <td> and zip() it to dict() with the list of column headers:
data.append(
dict(zip([x.text for x in soup.select('thead th')], [x.text.strip() for x in row.select('th,td')]))
)
Example
import pandas as pd
import requests
from bs4 import BeautifulSoup
url_list = ['https://www.coingecko.com/en/coins/ethereum/historical_data/usd?start_date=2021-08-06&end_date=2021-09-05#panel',
'https://www.coingecko.com/en/coins/cardano/historical_data/usd?start_date=2021-08-06&end_date=2021-09-05#panel',
'https://www.coingecko.com/en/coins/chainlink/historical_data/usd?start_date=2021-08-06&end_date=2021-09-05#panel']
data = []
for url in url_list:
response = requests.get(url)
src = response.content
soup = BeautifulSoup(response.text , 'html.parser')
for row in soup.select('tbody tr'):
data.append(
dict(zip([x.text for x in soup.select('thead th')], [x.text.strip() for x in row.select('th,td')]))
)
pd.DataFrame(data)
Output
| Date | Market Cap | Volume | Open | Close |
|---|---|---|---|---|
| 2021-09-05 | $456,929,768,632 | $24,002,848,309 | $3,894.94 | N/A |
| 2021-09-04 | $462,019,852,288 | $30,463,347,266 | $3,936.16 | $3,894.94 |
| 2021-09-03 | $444,936,758,975 | $28,115,776,510 | $3,793.30 | $3,936.16 |
EDIT
To get a data frame per url you can change the code to the following - It will append the frames to a list, so that you can iterat over to do things.
Note This is based on your comment and if it fits, okay. I would suggest to store the coin provider also as column, so you would be able to filter, group by, ... over all providers - But that should be asked in a new question, if matters.
dfList = []
for url in url_list:
response = requests.get(url)
src = response.content
soup = BeautifulSoup(response.text , 'html.parser')
data = []
coin = url.split("/")[5].upper()
for row in soup.select('tbody tr'):
data.append(
dict(zip([f'{x.text}_{coin}' for x in soup.select('thead th')], [x.text.strip() for x in row.select('th,td')]))
)
# if you like to save directly as csv... change next line to -> pd.DataFrame(data).to_csv(f'{coin}.csv')
dfList.append(pd.DataFrame(data))
Output
Select data frame by list index for example dfList[0]
| Date_ETHEREUM | Market Cap_ETHEREUM | Volume_ETHEREUM | Open_ETHEREUM | Close_ETHEREUM |
|---|---|---|---|---|
| 2021-09-05 | $456,929,768,632 | $24,002,848,309 | $3,894.94 | N/A |
| 2021-09-04 | $462,019,852,288 | $30,463,347,266 | $3,936.16 | $3,894.94 |